
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Archives
& Museum Informatics
158 Lee Avenue
Toronto, Ontario
M4E 2P3 Canada
info@ archimuse.com
www.archimuse.com
|
|
Search A&MI |
Join
our Mailing List.
Privacy.
Published: March 15, 2001.

Collage and Content-based Image Retrieval: Collaboration for Enhanced Services for the London Guildhall Library
Annette A. Ward , Margaret Graham, Jonathan Riley, Neil Eliot, and John Eakins, University of Northumbria at Newcastle, Nic Sheen, iBase Image Systems, Cathy Pringle, London Guildhall Library, United Kingdom
Abstract
Museum, library, archive, and other cultural heritage database collections are growing along with their numbers of users. Traditional methods of image retrieval will be insufficient. Content-based image retrieval (CBIR), a computer technique for retrieving images based on color, texture, and shape, locates visually similar matches for a selected painting, print, drawing, or other objects. The technique will become increasingly useful when combined with traditional methods of accessing images. Collage, the Corporation of London Guildhall Library and Guildhall Art Gallery 22,400 digital image collection, was selected as a test site for the application and evaluation of CBIR. The Institute for Image Data Research (IIDR) at the University of Northumbria at Newcastle and iBase Image Systems, developer of the Collage software, collaborated with the London Guildhall Library to introduce CBIR technology for image retrieval on the Collage web site. Initial evaluation of the CBIR feature by an online questionnaire indicated the majority of the respondents thought CBIR was useful, results were satisfactory and interesting, it was a good method to retrieve images, and they would like to use it again. Information derived from the results is important for developing and applying software to refine visual search retrieval.This research is supported by a grant from Resource: The Council for Museums, Archives and Libraries (CMAL/RE/103) and is part of an ongoing study, Evaluation of Content-based Image Retrieval in an Operational Setting, conducted at the University of Northumbria at Newcastle, Institute for Image Data Research.As museum, library, archive, and other cultural heritage collections grow along with their numbers of users, image retrieval using only traditional methods will become insufficient. Retrieving images by color, texture, or shape will be increasingly essential and especially useful when combined with traditional methods of accessing images by text data.
Content-based image retrieval (CBIR), a computer-derived technique for retrieving images based on elements such as color, texture, and shape, uses features of a selected painting, print, drawing, or object to find visually similar images. CBIR locates matches in a collection regardless whether they share key words with the original image.
Collage, the Corporation of London Guildhall Library and Guildhall Art Gallery online digital collection, was selected as a test site for the application and evaluation of CBIR. The web version of Collage comprises over 22,400 images of London from the 15th century to the present and includes paintings, drawings, sculptures, maps, and other images.
The Institute for Image Data Research (IIDR) at the University of Northumbria at Newcastle; iBase Image Systems, developer of the original Collage software; and the Corporation of London Guildhall Library and Guildhall Art Gallery collaborated to introduce CBIR technology for image retrieval on the Collage site. This endeavor is part of an on-going two-year research project based in the IIDR and funded by Resource: The Council for Museums, Archives and Libraries (formerly the Library and Information Commission).
This paper explains the procedures required to integrate content-based image retrieval within a museum's established online image collection. The collaborative partnership is described, content-based image retrieval (CBIR) is discussed, technical requirements and constraints are outlined, preliminary results of the user evaluation are reported, and future developments to the Collage site with application to similar collections are delineated.
Museum, Business, and Education Collaboration: Forming a Partnership
The objective of the project, funded by Resource: The Council for Museums, Archives and Libraries (http://www.resource.gov.uk) is to apply content-based image retrieval software in an operational setting and evaluate its effectiveness. Several considerations were made regarding selection of a site and its associated partners. Of critical importance was selecting an organization possessing a digitized image collection comprised of 10,000 or more images, a progressive outlook toward information retrieval, and the willingness to adopt new technology. Since technical expertise must be shared between a commercial business, iBase, and a university research institute, IIDR, it is also important to establish a relationship based on shared goals, shared outcomes, and trust. Confidentiality agreements may be required and consensus regarding credit or acknowledgement of contributions of partners must be agreed.
It is essential that each collaborator benefit from the partnership. In this instance, the Guildhall enhances their reputation by offering advanced search capabilities. Demographic information supplied by visitors to the questionnaire provides the Guildhall with a profile that helps their staff meet client needs and assist in directing services and products. Importantly, the Guildhall, a non-profit organization, does not incur expenses for application of the enhanced retrieval feature, conducting demographic research, evaluation of the system, and subsequent analyses. Expenses incurred are shared between the Institute for Image Data Research and iBase, freeing the Guildhall resources to accomplish their original mission.
Information collected regarding the users' assessment of Collage and content-based image retrieval provides essential information for the Institute for Image Data Research and iBase Image Systems as they develop and evaluate software to refine search retrieval and apply software to other collections. Research such as this is important to the future of information retrieval and the development of sophisticated software such as that used by the Guildhall Library.
The Corporation of London Guildhall Library and Guildhall Art Gallery and Collage
The original medieval library at the London Guildhall was founded in the 1420s through the will of Richard Wittington. The modern institution dates from 1824 and is divided into three sections, the Print Room, the Guildhall Library, and the Guildhall Art Gallery. The Guildhall Art Gallery houses over 4,000 paintings of which approximately 250 are exhibited at any one time in the newly renovated �83,000,000 facility. Together, the collections from the Print Room and the Guildhall Art Gallery present an extensive and comprehensive view of London and the foundation for Collage.
The collection includes paintings, engravings, maps, photographs, prints, and drawings of which most, but not all, relate to London. The majority of prints and drawings include topographical views of London from the 17th to the 20th centuries. Extensive collections of satirical prints, panoramas, and images relate to social themes. An unrivalled collection of London maps dating from the 16th century to the present includes parish, ward, borough, and thematic maps. Visitors to the Print Room have access to a local database containing images and information on 36,000 items. Due to copyright restrictions, visitors to Collage, the web database, have access to 22,400 of the total 36,000 images. The application described in this paper uses images exclusively from the web-based version of the Collage database.
Collage (Corporation of London Art Gallery Electronic), conceived in 1995 as an ambitious project to digitize the collection of the London Guildhall Library, resulted in a database in 1997 containing 36,200 works with associated text and indexing information. Phase two of the project delivered public access within the library via a simple user interface. This in-house database was translated onto the Internet at the end of 1998, producing the site at http://Collage.nhil.com.
At the time, Collage was the largest digital imaging project in Europe and faced many technical and curatorial challenges. These were successfully solved, leading the way for other organizations in the UK heritage sector to adopt similar systems.
iBase
iBase Image Systems was formed in 1992, as the result of collaboration between the founding directors and the National Museum of Film Photography & Television to provide an image database for an early photographic collection of 1920s racing cars for Zoltan Glass. iBase developed a revolutionary hard disk solution at a time when the average hard disk was only 100MB and PC graphics cards could only handle 800 x 600 pixels with 16 colors. The solution was adopted by other UK heritage institutions, including the British Library, the Natural History Museum, as well as others. iBase, catering to diverse requirements in the heritage sector, has provided the software for Collage since its inception, working closely with the London Guildhall Library to provide technical expertise to achieve their vision of a progressive database system.
Institute for Image Data Research
The University of Northumbria, based in Newcastle upon Tyne in the Northeast of England, was initially founded in 1969 as Newcastle Polytechnic and achieved university status in 1992. Approximately 23,000 students and 800 academic staff are based in arts; engineering, science and technology; health, social work, and education; social sciences; and business.
The Institute for Image Data Research (IIDR), established in 1997 as a multidisciplinary research institute, integrates researchers from computing, information and library management, psychology, art history, philosophy, fashion, business and management, and engineering to investigate relationships between images, computer technology, and people. Research has investigated aspects of image retrieval and how people search for, retrieve, and use images; impact of digital images on art historians; developing and testing software for retrieving trademark and historic watermark images; and assessing the feasibility of applying content-based image retrieval software in a variety of applications such as the one described in this paper. Additional information about the Institute is provided on the web at http://www.unn.ac.uk/iidr.
Content-Based Image Retrieval
The term, content-based image retrieval (CBIR), appears in literature as early as 1992 when Kato described his experiments to automatically retrieve images from a database by color and shape. Since then, the term has been widely used to describe the process of retrieving images from a large collection on the basis of features such as color, visual texture, shape, structure, and line that are automatically detected from images themselves. Retrieval of images by keywords, subject descriptors, or indexing terms is not CBIR, even if the keywords describe the content of the image.
Image databases differ fundamentally from text databases. Computer files of images are essentially unstructured since they consist purely of arrays of pixel intensities with no inherent meaning. Consequently, it is important to extract useful information from the pixels; i.e., recognizing the presence of particular shapes or textures before further computer processing. Once that is accomplished, images are then mathematically characterized and mathematically compared to one another to determine their visual similarity. However, in text databases, raw data are words stored as ASCII character strings that have been logically structured by the indexer (Santini & Jain, 1997).
Research and development issues in CBIR cover a range of topics, many of which are shared with traditional image processing and information retrieval. These include: (a) understanding image users' needs and information-seeking behavior, (b) identification of suitable ways of describing image content, (c) matching query and stored images in a way that reflects human similarity judgments, and (d) providing usable human interfaces to CBIR systems. A detailed review of CBIR is provided by Eakins and Graham (1999).
Characteristics of Image Queries
The kinds of queries users are likely to put to an image database are affected by user needs; why they seek images, their use of images, and how they judge the usefulness of the images retrieved. Although results are limited in this area, research at IIDR suggest there are seven discernable classes of image use which include illustration, information processing, information dissemination, learning, generation of ideas, aesthetic value, emotive/persuasive, and scalar attributes (Conniss, Ashford, & Graham, 2000).
Access to a desired image from a repository might thus involve a search for images depicting specific types of objects or scenes evoking a particular mood, or simply containing a specific texture or pattern. Potentially, images have many attributes that could be used for retrieval, including: (a) presence of a particular combination of color, texture, or shape features (e.g., green sparkling stars); (b) presence or arrangement of specific types of objects (e.g., chairs around a table); (c) depiction of a particular type of event (e.g., a football match); (d) presence of named individuals, locations, or events (e.g., a celebrity greeting a crowd); (e) subjective emotions one might associate with the image (e.g., happiness); and (f) metadata such as who created the image, where it was created, and when it was created. Each successive query type with the exception of the last, represents a higher level of abstraction than its predecessor, and each is progressively more difficult to satisfy. This leads to a classification of query types into three levels of increasing complexity (Eakins, 1998).
Classification of Search Queries
Classification of query types can be useful in illustrating the strengths and limitations of different image retrieval techniques. This was important in this application when selecting software for application in this project.
Level 1 comprises retrieval by features such as color, texture, and shape or the spatial location of image elements. These are known as primitive features. Examples of such queries might include "find pictures with long thin dark objects in the top left-hand corner," "find images containing yellow stars arranged in a ring," or more commonly, "find more pictures that look like this." This level of retrieval uses features, such as a given shade of yellow, that are both objective and directly derivable from the images themselves. Its use is largely limited to specialist applications such as trademark registration, identification of drawings in a design archive, or color matching of fashion accessories.
Level 2 comprises retrieval by derived features, sometimes known as logical features, that involve some degree of logical inference about the identity of the objects depicted in the image. It can be divided further into: (a) objects of a given type (e.g., "find pictures of a double-decker bus"), and (b) individual objects or persons (e.g., "find a picture of the Eiffel Tower"). To answer queries at this level, reference to additional knowledge beyond the image itself is normally required, particularly for more specific queries at level 2(b). In the first example, 2(a), some prior knowledge is necessary to identify an object as a bus rather than a truck. In the second example, one needs knowledge that a given structure has a given name "the Eiffel Tower". Search criteria at this level, particularly at level 2(b), are reasonably objective. Generally, this level of query is encountered more than level 1. For example, most queries received by newspaper picture libraries generally fall in this category (Enser, 1995).
Level 3 comprises retrieval by abstract attributes involving a significant amount of high-level reasoning about the meaning and purpose of the objects or scenes depicted. Again, this level of retrieval can be subdivided into (a) retrieval of named events or types of activity (e.g., "find pictures of Scottish folk dancing") and (b) retrieval of pictures with emotional or religious significance (e.g., "find a picture depicting suffering"). Success in answering queries at this level may require sophistication by the searcher. Complex reasoning, and often subjective judgement, may be necessary to make the link between image content and the abstract concepts represented. Queries at this level are often encountered in both newspaper (perhaps less common than level 2) and art libraries, such as those similar to Collage.
Presently, the most significant gap between the classification levels lies between levels 1 and 2. Many authors (Gudivada & Raghavan, 1995) refer to levels 2 and 3 together as "semantic image retrieval," and hence the gap between levels 1 and 2 as the "semantic gap." However, it should be noted this classification ignores a further type of image query, retrieval by associated metadata such as who created the image and where and when it was created. This is not because such retrieval is unimportant. It is especially important to museum collections. However, such metadata is exclusively textual and its management is primarily a text-retrieval issue.
Technical Application of CBIR to the Collage Web Site
User Requirements and Development Criteria
Application of content-based image retrieval software to the web-based version of Collage required a smooth transition with no confusion to users and no disruption to the standard web-based services. Additionally, it was important to: (a) establish use of CBIR as voluntary, (b) provide a simple mechanism for users to test CBIR within the Collage web site, (c) allow users the option to specify preferences on search parameters, (d) return results of the CBIR search in a format familiar to Collage users, (e) encourage users to complete the online questionnaire, and (f) develop a system that would work with common browsers. Development of the site also imposed technical considerations and constraints: (a) Regular activities of the London Guildhall Library could not be disrupted by the project; (b) service of the Collage site could not be adversely impacted during CBIR software application; (c) performance of the Collage site could not be diminished by introduction of CBIR; and (d) the user interface had to be independent of the CBIR software allowing different types of CBIR software to be applied and tested throughout the duration of the project.
System Design
Application of the CBIR software to the computer system comprised of five integrated stages consisting of creating the database, developing the interface to initiate the CBIR search, conducting the CBIR search, displaying results of the CBIR search, and developing the questionnaire. General testing of the site was simplified because of the modular architecture of the computer system. Components could be developed and tested before integrating the complete system (Figure 1).
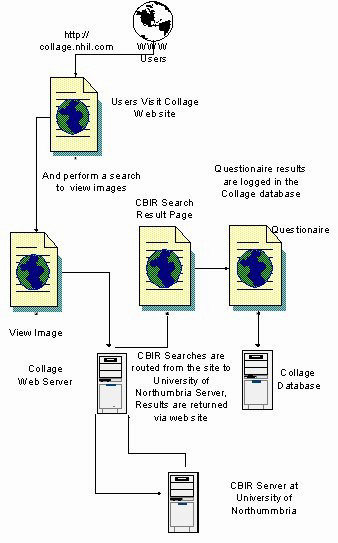
Figure 1. Logical design of the CBIR/Collage system illustrating distribution of processing between the Collage website and the Institute for Image Data Research at the University of Northumbria at Newcastle.
Creating the Database
Each image had three data fields, the identification number, feature vector length, and feature vector data, which is described in more detail in the next section. Although the entire Collage database consists of over 36,000 images which is used within the London Guildhall on its in-house computer system, due to copyright restrictions, only 22,400 images are used on the web database. Consequently, it was necessary to develop the database to filter out any non-copyrighted images.
Designing the Interface to Initiate the CBIR Search
The first content-based image retrieval software package used in this project is from Virage� Incorporated and includes the VIR Image Engine� 2.5, Virage� Core Library 2.1, and the Image Read/Write Toolkit 1.6. The software is embedded into the Collage system to perform two functions, image analysis and image comparison.
Image analysis is executed only once for the entire image database resulting in feature vector information, a mathematical representation of the visual content of an image. Image comparison involves assessing two feature vectors resulting in a score that quantifies image characteristics. Sizes of the feature vectors vary slight but are approximately 1.3 KB for each image, producing a database of over 44 MB for all of the images, and taking several hours to generate.
In order not to affect the general performance of Collage, it was decided to place the CBIR engine on a second server. This removed a heavy processing load away from the main Collage database, which is maintained exclusively by iBase, and shifting the maintenance and monitoring of the CBIR segment to the Institute for Image Data Research. Since it is imperative that both systems function compatibly; close communication between the IIDR and iBase regarding day-to-day systems management is maintained.
Conducting the CBIR Search
In order to activate content-based image retrieval on the Collage site, the user must begin with the traditional Collage search mechanism. A word must be entered in the search box or one of several search categories must be selected. When results are returned, the user may select a single image for closer inspection and conduct a "Standard Visual Search" or an "Advanced Visual Search" (Figure 2).
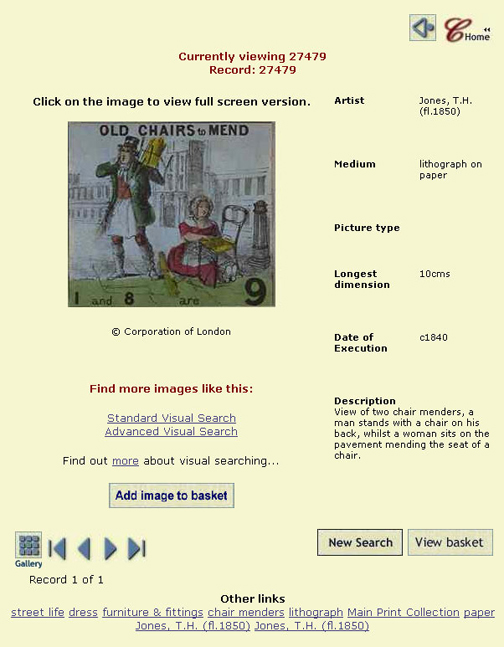
Figure 2. A "Standard Visual Search" or an "Advanced Visual Search" may be conducted once a specific image has been selected from a Collage traditional search.
When a user conducts a "Standard Visual Search," search parameters are set at default values. Color is set at 1, visual texture at 60, and shape or structure (in the case of Virage�) at 30 out of a possible 100 for each component. The Virage� system requires that each parameter must be set at a value greater than 0. Testing of the "Standard Visual Search" determined optimum values for producing the most desirable matches.
When an "Advanced Visual Search" is conducted, the user ranks "colors in the image," "visual texture in the image," and "shapes in the image" on a five-point Likert-type scale indicating the characteristic as "not at all important" to "very important" (Figure 3). Values are assigned to each button on the scale with "not at all important" set at 1, and subsequent buttons set at 20, 40, 60, and 80, respectively. When CBIR is initiated, the identification number (ID) and feature vector data of the selected image are read. Data for all images in the database are also read, and using Virage� routines, a similiarity measure is produced and stored, together with the ID for recall later. Searching all the images and producing the results takes about 10 seconds.

Figure 3. Parameters for the "Advanced Visual Search" are selected by the user who indicates their preferences regarding the importance of color, visual texture, and shape.
Displaying Results of the CBIR Search
At the end of conducting a CBIR search, measures for the entire Collage database are sorted in ascending order. However, only the first 18 images are collected for potential viewing. Although 18 images are returned, only 8 in addition to the original image are displayed. Because the database contains over 10,000 images for which the London Guildhall Library does not hold the copyright, those images are excluded from transmission over the web. A surplus of images insures a sufficient amount when non-copyrighted images are eliminated. Additionally, because Collage displays 9 images with its traditional searches, it was decided that the CBIR results page should use the same 9 image-format (Figure 4.)

Figure 4. Results of the search are displayed using a gallery format similar to the tradition Collage gallery.
Developing the Questionnaire
While the technical system was constructed, the questionnaire was developed. The questionnaire, only accessible after using the CBIR function, was designed to assess information useful to all three collaborators. Questions regarding the CBIR function including usefulness of the feature, satisfaction with the results, and enjoyment of the experience were devised. Additional questions were developed to collect data regarding general use of the web and the Collage service, along with demographic information about the users. Format of the questionnaire, designed to match the original Collage site was tested on browsers to ensure compatibility on alternate systems. The questionnaire was pilot tested with a panel of experts and questions revised before the final instrument was integrated into the Collage web site.
Data collection commenced in November and recruitment to the site was initiated in December through University classes. Data will be collected throughout the 2001. However, preliminary responses to the introduction of CBIR on the Collage web indicate interesting trends.
Preliminary Results of the Questionnaire
By mid-January, the 31 visitors to the site had completed the questionnaire. They consisted of 11 males (36%) and 14 females (45%). Age was fairly well distributed between the categories of 16-25 at 13%, 26-35 at 23%, and 36-45 and 46-55, both at 16%. Educational categories most frequently reported by the users as their highest level of achievement was "degree" and "masters" with 26% and 29% of the respondents, respectively. Most individuals were employed fulltime (32%) whereas 26% were students and most were UK residents (81%). It should be noted that most questions had some non-responses.
Half of the 31 respondents indicated this was their first time to use the visual image search on Collage, whereas 10 of the respondents reported using the feature two or more times. The majority of the users (74%) reported they would like to use the feature again with almost 71% responding they would use it "sometimes," "often," or "always".
Respondents indicated that over one-half (52%) of the images retrieved by the CBIR software were good matches to the original, whereas nearly 31% of the images were not. Interestingly, over 45% of the users "agreed" or "strongly agreed" that results of the search met their expectations. The same percentage "strongly agreed" results were useful and were satisfied with what was retrieved. Over one-third of the users found what they wanted by using the visual search.
Nearly three-fourths of the respondents "agreed" or "strongly agreed" that results of the search were interesting and they would like to use the visual search again. Although 58% of the users responded the visual image search was a good method of retrieving images, nearly one-third responded negatively or "neither agreed nor disagreed" with the statement.
Almost 75% of the users "agreed" or "strongly agreed" the search was fast and easy to use. Interestingly, 39% of the respondents liked the visual search better than a word search and 39% were ambivalent ("neither agree nor disagree"). Only three respondents provided a negative rating of this item.
Approximately the same percentage of users (42%) "agreed" the search was fun to use as compared to the percentage who "strongly disagreed," "disagreed," and "neither agreed nor disagreed." Clearly, reaction is mixed; however, none of the respondents indicated they "strongly agreed" with the statement that the search was fun to use.
About half of the respondents had visited the Collage site before. Approximately 40% were told about the site, whereas 16% found it by accident. Several, 42%, visited the Collage site to browse. However over 45% were there to look for a particular print or research the art collection.
Future Development and Application
Research regarding enhanced search capabilities, such as content-based image retrieval, is important to the future of information retrieval and the development of sophisticated software such as that used by the London Guildhall Library and Art Gallery and other museums, libraries, archives, and cultural heritage organizations. Growing collections necessitate image retrieval technology that expands search capability beyond traditional word-based indexing. However, there is much room for improvement and advancement.
For example, a hierarchical CBIR search initiated with a small number of images that have very different characteristics would allow the user to meander through the collection based only on visual criteria. This would provide search capabilities that would expand the breadth and depth of the returned images instead of being a linear exploration. Additionally, using CBIR technology on specific areas of an image to extract particular elements of an image would be an equally exciting advance, as well as a useful development.
CBIR may be also used to aid indexing of large collections, particularly for subjective terms which would greatly benefit the heritage sector. While digitization is a significant cost of any project, cataloguing and indexing of the resultant images is often equally costly. Speeding up and simplifying this process by identification of similar images is an attractive proposition, although it would require a detailed study to deliver a practical solution.
With respect to the Collage site and the introduction of CBIR, several enhancements can be made. Increasing the number of returned images from the CBIR search will provided users to peruse a greater selection of items. Allowing the user to conduct consecutive CBIR searches will allow the individual to refine the search experience.
References
Conniss, L. R, Ashford, A. J., & Graham, M. E. (2000). Information seeking behaviour in image retrieval: VISOR I final report. (Library and Information Commission Research Report 95). Newcastle-upon-Tyne, United Kingdom: University of Northumbria at Newcastle, Institute for Image Data Research
Eakins, J. P. (1998). Techniques for image retrieval. Library and Information Briefings, 85, London: South Bank University.
Eakins, J. P., & Graham, M. E . (1999). Content-based image retrieval (A report to the JISC Technology Applications Programme). Newcastle upon Tyne, United Kingdom: University of Northumbria at Newcastle, Institute for Image Data Research.
Enser, P. G. B. (1995). Pictorial information retrieval. Journal of Dcoumentation, 51(2), 126-170.
Gudivada, V. N. and Raghavan, V. V. (1995). Content-based image retrieval systems. IEEE Computer, 28(9), 18-22.
Kato, T. (1992). Database architecture for content-based image retrieval. Proceedings of the International Society of Optical Engineering, USA, 3846, 112-123.
Santini, S. & Jain, R. S. (1997). The graphical specification of similarity queries. Journal of Visual Languages and Computing, 7, 403-421