
Papers

Reports and analyses from around the world are presented at MW2005.
| Workshops |
| Sessions |
| Speakers |
| Interactions |
| Demonstrations |
| Exhibits |
| Best of the Web |
| produced by
|
| Search A&MI
|
| Join our Mailing List Privacy Policy |
3D Worlds and Cultural Heritage: Realism vs. Virtual Presence
Nicoletta Di Blas, Evelyne Gobbo, and Paolo Paolini, HOC-DEI, Politecnico di Milano, Italy
Abstract
3D graphics are evidently appealing for cultural heritage communication: the possibility of (re)creating environments, buildings, objects, etc. raised great expectations, both with professionals and end-users. Actual applications, however, have turned out not be so successful as they had promised to be. Therefore we must rethink goals (what can 3D be used for?), requirements (which features should we try to achieve?) and design (how do we do it?). This paper deals with a specific niche, i.e. shared 3D worlds accessible by several users (represented by avatars) over the Internet; some of our considerations, however, can probably be extended to other types of environment. Our main point is that shared 3D worlds are effective not just because they offer a realistic reconstruction of something, but because they have the property of creating (if well designed) virtual presence, i.e. the feeling of 'being there' with someone else, engaged in some kind of activity. We argue that, if virtual presence is what we look for, the main concern should switch from the quality of the graphics to the quality of the overall design of the application. The paper discusses the above issues on the basis of the experience gained in 3D educational projects developed by the HOC laboratory of Politecnico di Milano: SEE – Shrine Educational Experience (in cooperation with The Israel Museum, Jerusalem), Learning@Europe (in cooperation with the International Accenture Foundation) and Stori@Lombardia (in cooperation with the Regional Government of Lombardy). These projects have so far involved more than 1400 students and teachers from all over Europe. All these projects are an evolution of Virtual Leonardo, winner of the prize as “best on-line exhibition” at Museums and the Web 1999.
Keywords: virtual presence, cooperative 3D world, 3D graphics, interaction, proxemic semiotics, edutainment, e-learning.
Introduction
3D graphics have been considered, in recent years, a promising communication means for Cultural Heritage. Virtual Reality (VR) in particular has been considered a way to make museums, archeological sites, objects, etc. visible and/or interactive. From a graphical point of view, these environments are designed to be as detailed (i.e. corresponding to the real environment) as possible, and also aesthetically pleasant. If we consider immersive 3D environments, in which users can enter and move around, realism is considered a further, fundamental requirement: the physical behaviours of the real world are reproduced. Several interesting experiences of 3D virtual realities have been created with the above assumptions.
However, user experiences with these environments have turned out, sometimes, to be unsatisfactory (or not as positive as expected). After a bit of exploration, the interest of the user wanes, for, on one hand, no matter how carefully reconstructed the place is, the experience cannot be compared to the real-world experience, and, on the other, no meaningful goal is offered to trigger interaction. The magic of the real experience is not there; the engagement is low, the information conveyed is not rich enough.
We claim that an interesting goal for 3D technology is to create a place where people can have a meaningful experience by meeting other people. To this aim, a 'faithful reproduction' of a 'real' place is of no use: a fundamental role is rather played by virtual presence; that is, the sense of 'being there' with the other visitors of the 3D environment. A strong sense of virtual presence is achieved by means of accurate design of the application, including effective graphics and a well-planned interaction.
The paper discusses the above issues based on the experience gained on 3D projects developed by the HOC laboratory of Politecnico di Milano: SEE – Shrine Educational Experience (in cooperation with The Israel Museum, Jerusalem), Learning@Europe (in cooperation with the International Accenture Foundation) and Stori@Lombardia (in cooperation with the Regional Government of Lombardy). All these projects are an evolution of Virtual Leonardo, winner of the prize as 'best on-line exhibition' at Museums and the Web 1999 (Barbieri et al., 1999, and other works by the same authors).
SEE (Shrine Educational Experience; Di Blas, Hazan & Paolini, 2003 and Di Blas, Paolini, Poggi, 2003) was a project developed in cooperation with The Israel Museum, Jerusalem, dealing with the Dead Sea Scrolls (preserved in the Shrine of the Book at The Israel Museum, Jerusalem) and related topics (including history, religion, and anthropology). It was aimed at students from 13 to 18 years of age, both from Israel and Europe. The project underwent a massive testing phase, from November 2002 to May 2004, involving approximately 1400 students from Europe and Israel. The educational goals of the project were fully achieved, and users were strongly engaged by their experience with the 3D environment.
Building on our experience gained with SEE, the HOC laboratory is currently developing two similar projects: Learning@Europe and Stori@Lombardia. Learning@Europe is sponsored by Accenture Foundations (as part of the Accenture Corporate Citizenship investment program) and executed in cooperation with Fondazione Italiana Accenture; it is aimed at European high school students and deals with European history. It has already undergone a first testing phase, in November 2004, with Italian students only. From February 2005 to May 2005, more than 60 classes (approximately 1200 students) from 6 different European countries will participate. The project Stori@Lombardia is also based on the same format, but it deals with Lombardy region's history, and will involve more than 1000 Italian students in the same period.

Fig 1: SEE – Shrine Educational Experience (www.seequmran.it) An avatar in the games' space

Fig 2: Learning@Europe (www.learningateurope.net) The city dome

Fig 3: Stori@Lombardia (www.storialombardia.it) The courtyard of the castle
These projects have a common feature: there is an overall educational 'experience' (lasting approximately 6 weeks), within which 3D worlds play a well-defined role. In the virtual environment students 'meet' the other students, play with them, discuss with them (via chat), etc. The key success factor is the feeling of 'being there' all together, the so-called virtual presence: it is almost impossible to convey in words, or even with a demo, the emotion of a real session of use, when students from faraway countries meet together on-line and start cooperating, playing, discussing all together.
Virtual Presence
Virtual presence (Carassa et al., 2004; MacIntyre et al, 2004; Presence, 2004) is not an exclusive prerogative of 3D worlds: it can be achieved using a variety of technologies (including photographs, movies, phones, paintings, etc.). We will confine our discussion to the virtual presence that can be achieved through (shared or not shared) 3D environments. There are several different opinions about what virtual presence is exactly, what it is useful for, and how it can be achieved.
What Virtual Presence is
There are many definitions of virtual presence, all sharing a common trait: for virtual presence, people must feel themselves to be somewhere different from their actual location. Experts disagree about the nature of the 'where' to which the person is projected. We can basically distinguish three main opinions: the first is that the user is projected to a replica of a real place (e.g. a palace, an ancient location, etc.); the second is that the user is projected to a fictitious (more or less realistic) environment (e.g. what videogames do); the third is that the user is projected to a situation, where by situation something more complex than 'place' is meant.
Being in a replica of a real place (whether the place is still existing or not) has the ambition of mimicking the real experience; paintings, photographs, drawings, movies, virtual environments of this kind share this goal: almost pure 'physical illusion' is at stake. Being in a fictitious place is more about imagination, since the place reproduced does not claim to be real. Eventually, a 'situation' is a dematerialized reality: think for example of people immersed in a telephone conversation: they feel detached from their physical situation and oblivious of the technological means they are using (in fact, they often gesticulate, as if they could be seen!).
How Virtual Presence Can Be Effective
A 3D application can have one (or more) of the following goals:
a) Understanding how a real place is (or was): e.g. allowing a user to explore the ancient Roman city of Pompeii or a far-away museum.
3D worlds, after the great promises of 10-15 years ago, have not fully succeeded in achieving this goal. For existing environments (such as museums or churches), pictures (possibly the panoramic ones) or movies or other traditional means have often been more effective (and less expensive!).
As far as no-longer existent environments are concerned, 3D worlds have scored better, but still less than expected, in the sense that users turned out not to appreciate them so much. The problem is even more acute when we consider shared 3D environments that are characterised by an inherent reduction of visual quality.
b) Conveying the 'emotion' of being in a real place: e.g., recreating the emotion related to the above experiences.
If point a) (above) has resulted in partial disappointment, we must speak of complete failure on this aspect. The insufficient visual quality, the evidence that what we call 3D is actually displayed on a flat (2D) screen, the lack of other sensorial features, are all obstacles to the emotion-raising capacity of these environments. Any visitor who would feel almost overwhelmed when entering the premises of a famous museum, feels no emotion at all when entering a 3D reconstruction of it; surprisingly (or not?), we find the same lack of emotion also for archaeological reconstructions, where the 3D replica has more details and more things to look at than the 'real' object which is only partially visible (or not visible at all).
c) Creating the illusion of being in a 'fantasy' place: e.g. fairy places in which videogames take place: we know that they do not exist, but still we feel an emotional attraction for them.
The user may feel somehow 'immersed' in a fantasy place, having no real experience to compare it with; still, the experience is more rational than emotional: all the details are available, the world is too shallow to explore.
d) Creating an immaterial situation: e.g. a conversation among peers, a teaching-learning situation, a competition, etc.
This is, in the end, and as far as our experience goes, the most effective kind of virtual presence we can create. A variety of technologies can be used to create situations where users feel engaged in an activity where to some extent they forget about technology as such. A shared 3D world, for example, offers quite a crude solution: a visually poor fictitious 3D rendering (remember that the screen is flat!), a chat, some very simple avatars moving around, etc. Given careful design of the activities (people do not have just to move around purposelessly, as we shall argue below), this is enough to create situations where users feel immersed 'in the situation', oblivious of technology.
How Virtual Presence Can Be Achieved
Situational virtual presence is not achievable by reproducing a virtual copy of a 'real-life place', but rather by focusing on what goes on in the situation, and trying to put the users in the best position to 'feel part of the situation'. Assume, for example, that the situation is a 'virtual classroom' where pupils can ask questions of the teacher, and get answers: in the real life situation, pupils must raise their hands, the teacher selects one of the pupils, the pupil asks the question (that everybody can hear), the teacher either dismisses the question or provides an answer (that everybody can hear); in the meantime, pupils may chat in low voice. Creating the situation (in view of achieving a feeling of virtual presence) is not about recreating the physical room, or simulating raising hands, or adding the audio to reproduce the classroom chatting. The effect of virtual presence can be achieved if the mutual interaction among students and with the teachers is as effective and 'natural' as the real one, not because the physical features of the real world are reproduced, but rather because both teachers and pupils are focused on the question-answering activity, and being engaged in this interaction, do not even perceive the technological medium binding them together.
Building Effective 3D Worlds
In this section we explain how good design of the interaction rules and of the graphics for shared 3D worlds can effectively help achieve a sense of virtual presence and therefore make the overall experience (be it educational, entertaining, informative…) effective and satisfying for the users. We assume, of course, that the purpose is to achieve some kind of virtual presence and not, for example, to show the features of an archaeological monument, as was the case, for example, of the beautiful Olympia project of the Powerhouse Museum (Kenderdine, 2001). Examples will be taken from the three projects we introduced in the first paragraph: SEE, Learning@Europe and Stori@Lombardia.
Interaction Requirements
Interaction is a complex feature, creating engagement and excitement on its own. In 3D shared worlds each user interacts not only with the world but also with the other users; therefore, a careful balance must be found: interaction with the world (and the objects in it) must be interesting on its own, but at the same time it can't distract the user from interaction with the other users (which is the main motivation for having a shared environment). For this reason, it is not viable just to let the users into the shared world, hoping that something will happen: there must be careful planning of activities.
Planning The Experience In The 3D World
In all the above projects, 8 students (from 4 different classes) access a 3D world simultaneously, for a one-hour-long 'session' of use. The sequence of actions must be carefully planned, but within each step, room for 'spontaneous' interaction must be provided. A careful balance between 'Do what I want you to do', and 'Do what you want' must be found.
Figure 4 shows the educational plot for the first session of Learning@Europe.

Fig 4: Learning@Europe (www.learningateurope.net): the sequence of activities of the first session of use
After a welcome phase (during which users log into the world and start practising its advanced features – flying, chatting, whispering, etc.), a first 'lesson' takes place: the guide introduces the environment students find themselves in by means of boards (i.e. pop-up windows); then a self-presentation of all the participants takes place in 4 different, though similar, environments (4 domes, of different colours, each associated with a different town). Finally a short recap of the session takes place; the guide gives the assignment for the next meeting (in this case, studying material and preparing a team's presentation); and everybody says goodbye. This very detailed storyboard motivates avatars to move around and do things; moreover, the concrete tasks given, as well as clever hints by the guide, enhance chat interaction with the other 3D world's visitors (treasure hunts and quizzes will take place, during which students will have to take decisions together). The guide keeps the action fast paced and engaging so that none of the participants feels bored or cut off from the action.
Features Of The Avatars: How 'Powerful' They Should Be
The designers of a 3D world decide what avatars can do, must do, can't do and when. Once 'realism' of behaviour is not the driving paradigm, a new set of requirements must be devised. Avatars can perform many actions, some similar to real world ones (such as walking around), others completely new (such as flying, seeing through other avatars' eyes, activating boards and hotspots from everywhere – as if they could stretch their hands reaching everywhere, etc.). What must be noted is that if we design a totally powerful avatar, then its physical presence in the 3D world paradoxically becomes almost useless: if anything can be done from anywhere, then in a certain sense the avatar is already everywhere in the environment: why should it move around? It is as if we could buy a newspaper from home, by clicking on a hotspot: why should we dress and go out? Therefore, the first lesson to be learned is that if we want to make use of the physical representation of the avatar and also of the 3D environment (such as stairs, labyrinths, etc.), the avatar must not be allowed any power, at least not in any moment! The designer selects what powers avatars are given according to the activity they're expected to perform. For example, in all our projects, a treasure hunt takes place: avatars have to look for objects hidden in a labyrinth. Of course, during the treasure hunt flying is forbidden: otherwise, they would spot the object almost immediately! On the other hand, avatars can be forced to use some features: for example, again during the treasure hunt, an object can be selected as the right one only after consultation. Therefore when players find an object they deem correct, they ask their mate to check it by looking at it through an avatar's eyes.
A very important consequence of the powers avatars are given or not given concerns what is called proxemic semiotics. By proxemic semiotics we mean – taking the term in broad sense with respect to its scientific meaning (Hall, 1966) – all the signs we convey by means of our actions and position in space. In moving, gesturing, living, we produce signs clearly readable by those around us. They are culturally determined (for example, we shake hands when we meet) or, so to speak, natural, spontaneous. These last signs are not meant to be signs; that is, there isn't a semiotic intention behind them (for the distinction between intentional and non-intentional signs see Bobes Naves, 1989). In other words, we generally don't open a door to show that we're entering a room, but because we want to enter a room; in doing so, nonetheless, we make it clear for those who see us that we are actually moving towards another room. A totally powerful avatar that can do anything from anywhere fails to convey all the proxemic signs: when we spot an avatar standing still, we do not know what its human-master is doing: is s/he looking at a board? Chatting with the others? Is s/he busy or idle, willing to be involved in a conversation?
A lot of work is required in this very promising area of research, the basic question of which is: what physical constraints of the real world should be kept (and in which situations) in order to save the signals conveyed by the gestures and positions implied by them? In our projects, we have started implementing some features and rules so as to preserve some of them.
Example 1: in order to move from one environment to the other (say from the meeting point to the labyrinth), we have the technical possibility of forcibly dragging all the avatars behind the guide. Although we keep this chance for 'desperate' situations (when one user is left behind all alone), avatars are required to follow the guide and physically pass through a door (or something similar). This enhances the sense of being together: stray avatars tend to follow the others (hoping they are not stray avatars too!), if they can't spot the guide. They try to find the right place ('enter through the blue door!'), they chat with the others if they need help in orientation. If the guide simply moved all the avatars from one place to another, a lot of cooperation would be lost.
Example 2: Avatars reading boards apparently 'do nothing'; they might even be very far from the board they are looking at. We decided in Learning@Europe to make it compulsory to be close to a board in order to be able to open it. In this way, all the users can see that an avatar is performing that specific action (that is, reading that board), and can decide, for example, to start up a conversation with the avatar on that topic.

Fig. 5 Learning@Europe (www.learningateurope.net). What is this avatar doing?
Example 3: When someone wants to whisper to someone else, the name of the addressee has to be selected. But there's no relation between the space and the people 'speaking': they can be very far in the virtual world, so none can notice there's a conversation going on and join in. A possible solution could be, at least in some situations, to make it compulsory for users to be physically close in order to be allowed to whisper.
The above are just few examples of the proxemic consequences of the designers' choices: every limitation or power, imposed/given or denied to the avatars, implies the survival or disappearance or translation of those spatial signs of which, in the real world, we make such large use. The issue is: in view of achieving virtual presence, what proxemic signs of the real world (implementing its physical limitations) should be imported into the virtual world? What other signs should be somehow 'translated' into the virtual world, so as to save them? What others should be simply ignored?
Graphic Requirements
Reproduction Of A Real Place
Our main point is that realism in the replica of a real space (e.g. a city, a building, a monument) is not relevant: being very detailed in the graphics or close to the original would not make much of a difference for users. The emotion (virtual presence effect) of being there would be missing anyway. At most, an allusion can be effective: the same technique used in theatre can be used in 3D worlds. As it is impossible to reproduce the city of Venice in a theatre for the play Othello, some simple objects will serve the purpose of alluding to the famous city: some striped poles will do for canals, gorgeous pieces of furniture will allude to the interior of a noble palace, etc. Since full realism is not achievable, allusion is sufficient, and can be emotionally very effective: the audience 'feels' that the action is in Venice (with the 'magic' of the city missing, of course). A similar strategy can be used for 3D applications: a few rough architectural elements can suggest that the action tales place in The Israel Museum, Jerusalem, or in the Science and Technology Museum in Milan. Detailed modelling is useless, since it would not add anything to the user's emotional experience.
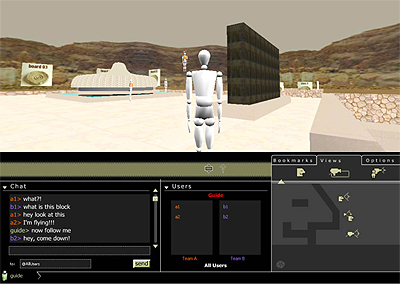
Fig 6: SEE, Shrine Educational Experience (www.seequmran.it). The white dome and the basalt wall of the Shrine of the Book
Spatiality
As regards spatiality, two different concerns must be kept in mind:
- there must be enough room for the avatars to move around, without colliding too often
-
there must be something interesting enough to spur users to move around and explore.
Exploration by the avatars can be spontaneous (they want to look around) or forced by the interaction's design (see the corresponding section): e.g. users can be asked to reach some specific spots, to look for objects, to pass through a door, etc. We must keep in mind that virtual spaces get explored only if there's a good reason to do so: e.g. getting different points of view or being able to perform some kind of otherwise impossible interaction. It is therefore important to not exaggerate with 'cameras' (allowing avatars to look around without moving) or with interaction capabilities (allowing avatars to manipulate far away objects); as we have already said in the last section, too powerful features would make it pointless for the avatars to move around.
Distance, Depth And Size Of The Objects
Another issue is the feeling of 'distance' and 'depth': we know (and painters too know very well) that we have a number of clues in order to guess the distance of objects: we can use 'apparent size' of well known objects (a car smaller than a person, for example, must be more distant than a person), the convergence of lines, shading, light, etc. Our opinion is that the size of the objects is very important in keeping the illusion, even if realism is not at stake: a door or a ball should have a size that makes sense with respect to the size of the avatars, in order to keep an overall consistency of the world. Textures are very helpful in conveying the impression of depth: geometric, striped textures are much more effective in this respect than homogeneous textures that convey the impression of a flat surface. In other words, a user who is represented by avatar A who sees 4 lines on the floor separating it from avatar B, and 6 lines separating avatar B from avatar C, will be able to tell immediately their relative positions in the virtual environment.
Precision Of Modelling And The Size Of The Space
Let us assume that the action takes place in an open area, where there is empty desert out to the horizon, or in a large room, with a window, from where a faraway city can be seen.
It is probably ineffective to try to model, graphically, a very large desert (with scattered objects in it) or a faraway city: the size of the graphical model becomes too big and the illusion is poor (when we tried, the far away city looked like a mess of confusing lines!). We suggest using texture instead, i.e. a drawing (e.g. of the desert or of the city) overlaid on a panel, giving the illusion that something is there, far away. Obviously, if an avatar reaches that place it will uncover the trick: the city is not there! That's just a panel with a drawing on it. But this is not a serious danger with respect to the achieved benefits: a more effective illusion and more economic graphic modelling. First of all, if the avatars behave, they won't go far away from where the action takes place, i.e. from where the other avatars are. Second, the tricky panels should not be placed too close to the action location, but at some distance: the avatars can start moving towards them, but it is very unlikely that they will actually reach them. Our students (more than 1500) never went so far away from the action as to uncover the trick!
Conclusions and Future Work
We can summarize our conclusions as follows:
- we should not consider 3D graphics as a unique field, even if we confine it within the realm of Cultural Heritage applications. If the technology is more or less common, different purposes (for building 3D environments) lead to different requirements and different design considerations
- the strong point of shared 3D environments is not realism but rather virtual presence (i.e. 'I am engaged in an activity with someone else'), to which realism or high quality graphics are not relevant issues
- in a shared 3D world the interaction of each user with the environment must be carefully balanced with the interaction with other users
- the design of features ('powers') of the avatars should consider psychological factors (such as fun, engagement, and proxemic semiotics), as well as technical factors
In terms of future work, our main effort today (besides making our 3D environments successful!), is to isolate the single features (say virtual presence, graphics, interaction, proxemic semiotics, etc.), trying to understand how each of them works; we shall try different alternatives and put them to test by measuring users' reactions.
Acknowledgments
We wish to thank all the people who work at the above projects (the development staff of Virtual Leonardo, SEE, Learning@Europe, Stori@Lombardia) and our partners (Museo della Scienza e della Tecnica di Milano, The Israel Museum, Jerusalem, the Accenture Foundation and the Regional Government of Lombardy).
References
Barbieri, T. (2000). Networked Virtual Environments for the Web: The WebTalk-I and WebTalk-II Architectures. IEEE for Computer Multimedia & Expo 2000 (ICME), 2000, New York, NY.
Barbieri, T., F. Garzotto et al. (2001). From Dust to StarDust: a Collaborative Virtual Computer Science Museum. ICHIM 2001 International Cultural Heritage Informatics Meeting, 2001, Milano, Italy.
Barbieri, T., P. Paolini et al (1999). Visiting a Museum Together: how to share a visit to a virtual world. Museums and the Web, 1999, New Orleans, LA.
Barbieri, T. & P. Paolini (2000). Cooperative Visits to WWW Museum Sites a Year Later: Evaluating the Effect. In D. Bearman & J. Trant (Eds.) Museums and the Web 2000: Selected papers from an international conference. Pittsburgh: Archives & Museum Informatics, 173-178. available http://www.archimuse.com/mw2000/papers/barbieri/barbieri.html
Barbieri, T. & P. Paolini (2001). Cooperation Metaphors for Virtual Museums. In D. Bearman & J. Trant (Eds.) Museums and the Web 2001, Selected papers an international conference. Pittsburgh: Archives & Museum Informatics, 115-126, available http://www.archimuse.com/mw2001/papers/barbieri/barbieri.html
Bobes Naves, M. (1989). La semiologíaf, Editorial Sintesis, Madrid.
Carassa, A., F. Morganti, M. Tirassa (2004). Movement, Action and Situation, in Presence 2004, Proceedings of the Seventh Annual International Workshop, Technical University of Valencia, Spain, October 13-15 2004.
Di Blas, N., S. Hazan, P. Paolini (2003). The SEE experience. Edutainment in 3D virtual worlds. In D. Bearman & J. Trant (Eds.) Museums and the Web 2003, Selected papers from an international conference. Toronto: Archives & Museum Informatics. 173-182. available http://www.archimuse.com/mw2003/papers/diblas/diblas.html
Di Blas, N., P. Paolini, C. Poggi (2003). SEE (Shrine Educational Experience): an Online Cooperative 3D Environment Supporting Innovative Educational Activities. ED-Media 2003, Honolulu, Hawaii, USA
Di Blas, N., P. Paolini, C. Poggi (2005?). A Virtual Museum where Students can Learn, in R. Subramaniam (ed.) E-learning and Virtual Science Centers, (at press).
Di Blas, N., P. Paolini, C. Poggi (2004). Learning by Playing. An Edutainment 3D Environment for Schools, in Proceedings of ED-MEDIA 2004. World Conference on Educational Multimedia, Hypermedia & Telecommunications, June 21-26, 2004; Lugano, Switzerland
Hall, E. T. (1966). The Hidden Dimension, Garden City, N.Y., Doubleday.
Kenderdine, S. (2001). 1000 years of the Olympic Games: Treasures of Ancient Greece: Digital Reconstruction at the Home of the Gods. In D. Bearman & J. Trant (Eds.) Museums and the Web 2001, Selected papers from an international conference. Pittsburgh: Archives & Museum Informatics, 163-176. available http://www.archimuse.com/mw2001/papers/kenderine/kenderdine.html
MacIntyre, B., J.D. Bolter, M. Gandy (2004). Presence and the aura of meaningful places in Presence 2004, Proceedings of the Seventh Annual International Workshop, Technical University of Valencia, Spain, October 13-15 2004.
Mirapaul, M., (June 1999). At this virtual museum you can bring a date. The New York Times on The Web.
Presence 2004, Proceedings of the Seventh Annual International Workshop, Technical University of Valencia, Spain, October 13-15 2004.
Cite as:
Di Blas, N., E. Gobbo and P. Paolini, 3D Worlds and Cultural Heritage: Realism vs. Virtual Presence, in J. Trant and D. Bearman (eds.). Museums and the Web 2005: Proceedings, Toronto: Archives & Museum Informatics, published March 31, 2005 at http://www.archimuse.com/mw2005/papers/diBlas/diBlas.html
April 2005
analytic scripts updated:
October 2010
Telephone: +1 416 691 2516 | Fax: +1 416 352 6025 | E-mail: