
Papers
Reports and analyses from around the world are presented at MW2005.
| Workshops |
| Sessions |
| Speakers |
| Interactions |
| Demonstrations |
| Exhibits |
| Best of the Web |
| produced by
|
| Search A&MI
|
| Join our Mailing List Privacy Policy |
MoMo: A Hybrid Museum Infrastructure
Javier Jaén, Vicente Bosch, Jose M. Esteve and Jose A. Mocholí, Polytechnic University of Valencia, Spain
Abstract
Museums are playing active roles in modern societies beyond preserving a society's cultural heritage. They have become an important learning environment, and some of them even are tourist attractions. But traditional storytelling aids for museums consisting of texts and labels may not be personalized to fit each individual personal taste and are static sources of information. This paper explores the notion of Hybrid Museum (HM) in which wireless personal digital assistants (PDAs) are used to tailor content to the visitor to enrich both the learning and entertainment experience. The customization and personalization of the displayed contents is achieved by implementing a modified Partial Prediction Matching algorithm and a distributed Ant Colony System algorithm to find optimal itineraries within the museum, even with constrained time.
Keywords: hybrid museum, PDA, ant colonies, prediction, .NET
Introduction
In the last few years, museum technology has experienced a revolution with the arrival of handheld devices capable of enhancing visitors' experiences by introducing multimedia content. This issue has been the focus of a great number of studies and projects: iTour (Manning, 2004), the Multimedia Tour (Wilson, 2004), GettyGuide (Marshak, 2003), MultiMuseum (Monaci & Cigliano, 2003), and Renwick (Larkin, 2004), among others. All these projects have evolved from the traditional storytelling for adults to other types of visits targeting audiences like children, teenagers, and art specialists. However, despite these efforts, there is still a lot of work to be done to obtain both dynamic, highly customizable, visits and simple mechanisms to explore large collections of related data.
In this paper we present the MoMo project, an example of a Hybrid Museum (Jaen, 2003). The MoMo project includes a mechanism for browsing large collections of explanatory items on PDAs and two different techniques to obtain dynamic and customizable itineraries. The first is a technique to analyze the behaviour of users when visiting different collections and to build stochastic predictors that may populate art collections according to their taste. The second is a natural algorithm (based on the behaviour of ant colonies) to build itineraries that are time constrained and maximize the number of popular artworks. These two proposed algorithmic approaches prove that we can obtain dynamic itineraries that better fit any visitor's taste and available time and increase the overall satisfaction of the visitor using a Personal Digital Assistant in the museum.
Exploring Very Large Data Sets on PDAs
By definition, the User Interface is the meeting point between the user and the program. Its design must take into account numerous elements which contribute to the general goal of making it useful. Our aim is to design the user interface for a multimedia navigation client on the PocketPC platform. Generically, a navigation client must be able to guide the user while browsing a vast amount of information, yet not overwhelm the user. Therefore, the fundamental issue to be faced is how information must be displayed so that it will be perceived and assimilated by the user in the most effective way. Three main requirements that have to be fulfilled by a multimedia content browser are functionality, simplicity, and generality with flexibility.
Functionality
Usefulness should be the main goal at every moment. Graphic designers should minimize their interface's learning curves, avoiding artificial approximations which may not be intuitive for the users. By doing so, we ease users' efforts when interacting with a software system and make their experience more gratifying.
Simplicity
The information provided to the user must be synthesized and, if possible, multimedia in nature. Multimedia information is very familiar to human perception and, consequently, very attractive. We must take into consideration that, although we may potentially navigate large amounts of information, this process should be transparent to the user. Users are not able to process large volumes of information simultaneously, and information will generally be ignored if we overlook this fact. Thus, it becomes necessary to rank or categorize information by applying criteria related to its inherent semantics. It would not be beneficial, however, to go completely in the opposite direction, and build an extremely compact and cryptic interface. In summary, in this kind of application, the solution that is designed must be intuitive enough so that every person is able to use it, regardless of their background knowledge.
Generality and Flexibility
Our solution must be versatile enough that it will be able to adapt itself to the range of domains in which it might potentially be used: museums, monuments, conferences, etc. Moreover, it is desirable to include enough flexibility to allow some degree of customization and information re-arrangement, given the limited screen size of PDAs.
Having these requirements in mind, we find current PocketPC application design is still excessively poor. The particular characteristics of the destination platform are usually disregarded in favour of portability criteria. Actually most PocketPC applications are designed simply as reduced versions of their equivalent desktop ones.
Moving into our field, today it is still difficult to find good solutions for Museums running on mobile devices. We have found the few existing ones to be excessively based on PC solutions. Form-based interfaces are usually chosen and, as a result, information appears to be compressed into insufficient space. In the best case, we find Web-based designs that instead of improving considerably the appearance of the austere interfaces we have just mentioned, forget completely about supplying an easy and useful navigation mechanism. We attribute this to two reasons: first, the amount of information that can be displayed on a Web page is much greater, and second, it is common practice to follow the design criterion of minimizing the number of mouse clicks that must be performed to reach every point of the Web. However, we must not forget that those design criteria are suitable only for PCs.
Therefore, applications that base their browsing mechanisms on a pure image dump, saturating the available space, are more than questionable in terms of usefulness. Even if we limit the number of visible elements and provide graphical mechanisms such as sliders, we are only helping with the management of a reduced number of elements. These approaches force the user to perform a linear search on the contents, and effectiveness is severely limited given the volume of information that has to be managed in a museum. In our opinion, assuming that some sort of classification is needed, this must not be just limited to a physical arrangement of files, but extended to cope with more complex classification schemes so that associations may be expressed in several ways, as in databases.
Another important factor related to interface design for PDAs is that pen-based interactions are much faster than their mouse-based equivalents on desktops. Hence, we have to reformulate some of the design criteria, like having a lower density of options in the screen to improve clarity at the expense of requiring one or two additional pen clicks. Those concepts have been applied in Museum-oriented solutions such as Sun Microsystems' Getty project. But the usefulness of their PC solution is not captured in the PocketPC equivalent. While information arrangement is accomplished, we find two serious limitations. First, the nature of the information is static, and therefore less attractive for the user. It would be improved by seasoning the contents with interactive explanations of what it is being presented. Second, by only including a Next button for navigation, users are forced to perform a linear search, as we commented previously, without the possibility of letting them explore as they please.
Even though it is necessary to provide enough versatility, we should not forget that we are designing a content navigation tool and, therefore, the main issue is the content itself. If we create a too complicated or badly designed interface, the user would be excessively distracted by the need to pay attention to the interface, getting disoriented rather than concentrating on the displayed contents. We believe it is possible to design complete solutions by extensively using hierarchical content navigation, setting a clear way for the user to know how information is organized. In our case, our approach can be described along several dimensions.
Information's Nature And Organization
One of our fundamental original requisites was that, for the best visiting experience, multimedia data had to be provided to users. The information that is supported in the current version consists of Macromedia Flash movies and any other multimedia format supported by Microsoft Windows Media Player, including video movies. As well, all these formats must be totally integrated within the application interface such that it becomes transparent to the user. In terms of organization of the information, we used a graph topology so that it is possible to establish relationships between any two arbitrary elements. The terminology we used in our project calls the basic data packet dissemination. Disseminations are associated by using ranked relationships called collections (Figure 1). This kind of associative arrangement allows different clustering levels of information that the user may navigate. It is even possible to classify the existing contents in accordance with the person's characteristics (age, level of knowledge, preferences, etc). Our final goal is to give the users just the information they may be interested in, adapting the navigation to their characteristics without limiting the ways they may want explore. Later in this paper we will discuss other mechanisms, besides clustering, to personalize information for the end users.
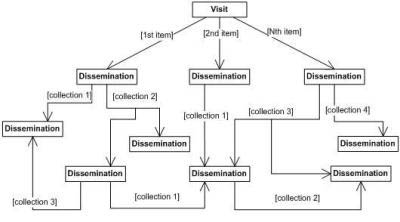
Fig 1: Clustered graph-like organization of information
Content Navigation
In order to support content navigation, a hybrid scheme supporting both fully guided visits and free navigation was created (Figure 2).
The user may navigate in a fully guided manner by sequentially exploring a set of proposed disseminations (Horizontal Navigation). These sequential disseminations may either be statically preset or dynamically generated, as we will present later, by some type of intelligent infrastructure.
At any time during the visit, a user who wants to know more about a particular dissemination may invoke the Navigation Browser. This browser is populated by clustering information in terms of collections and analysing the graph of available associations for the particular dissemination currently being observed. In our current implementation, the potential visited collections are Details about the artwork, Same historical context artworks, Previous artworks (which inspired the present one), and Miscellany. Entering a specific collection to know more about a particular dissemination triggers a different mode of navigation known as Depth Navigation.
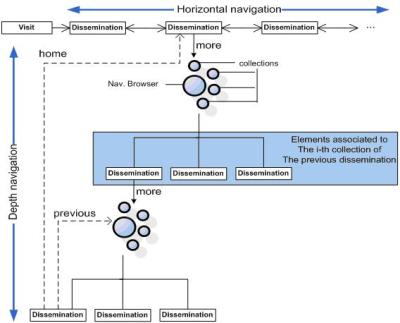
Fig 2: Types of Navigation
Depth Navigation allows the user to explore associations between disseminations at any level of nesting. Therefore, the user is not limited to following the initial, fully guided, sequential disseminations, but rather can browse the graph in a straightforward manner because information is clustered in terms of collections. Internally, depth navigation is supported by a navigation tree which stores the necessary data to allow the user to step back to the previous dissemination (Previous), or return to the dissemination from which Depth Navigation began (Home), emulating this way a functionality offered in most Web browsers that are familiar to average users. Moreover, there exists the possibility of performing a completely random navigation by using a special pad to enter a random artwork reference number. Once a user is located randomly at a given dissemination, Depth Navigation is also available to explore other related disseminations.
The Interface and the Navigation Browser
Because of usability issues discussed earlier in this section, we have tried to minimize the number of necessary navigation controls. We designed a small navigation bar located in the bottom left corner of the PDA screen to support Horizontal Navigation. The content is displayed in the central part of the interface, with its own a playback controller. Moreover, in the case of Flash movies, the client area responds to dragging and zooming, controlled by the PocketPC stick, enabling the user to pay attention to any especially interesting details.
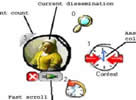
The Navigation Browser handles the Depth Navigation (Figure 3). The design of this control was especially important; the main goal was to create a versatile enough control that could be reused in any arbitrary PocketPC application. Using an appropriate skin, the Navigation Browser is also used in the Social Interaction module of our application, to display additional functionalities. The control is formed by a central element which comprises an image representing the current dissemination. Surrounding it, the icons corresponding to the available associated collections are arranged in radial disposition. Only a subset of the available options is shown simultaneously: the user can navigate these options by rotating them around the central element. There is also a fast scroll control designed to help accelerate the search. (This is normally not necessary due to the degree of hierarchy in the information.) The benefits of using this control are immediate: the high degree of reusability accelerates the learning curve for new users who just need to learn one control. Reuse also results in less coding, better program modularization, and easier Look&Feel updating.

Fig. 3: Anatomy of Collections Browser
The browser implementation was, nonetheless, not trivial, since the current version of the .NET compact framework does not natively support transparencies. Hence, we created, by using low level calls, a new Windows control class for the browser. This class supports animation and transparency features over any kind of background, a feature that is currently not present on any other PocketPC application.
To summarize, the problems identified earlier have been solved in our application by organizing information as a clustered graph which allows the establishment of any kind of associations among disseminations. Content is no longer limited to still images or text, but comprises all the multimedia range supported by both Macromedia Flash and Windows Media Player. The interface design is based on collection classification, supported by the Navigation Browser and some intelligent components that provide users with just the information they may be interested in, and finally, there is an attractive and easy-to-use interface supported by new featured controls not seen before on PocketPCs.
Predicting Visitors' Behaviour with Markov Models
Any PDA-based guidance application in museums of medium to large size has the challenge of presenting user-relevant information from huge quantities of data which in some cases might not be needed or wanted by the user, e.g. a user might not care about the historical context in which an artwork was made but might be interested in the painting process or in knowing about other related previous pieces of artwork of the same creator. Therefore, assuming that the explanatory items to be displayed in an itinerary are categorized in clusters such as (history, details, previous artworks ) it would be interesting to interpret how the user feels about these categories so that only the information most likely wanted is provided.
To achieve this goal, we have implemented and tested a stochastic prediction model which is based on high order Markov models. Prediction is performed by partial matching (PPM) algorithms to provide with a guess as to the user-preferred contents. This technique has also been used for data compression and Web pre-fetching (Chen, 2003) but there are two major problems with the algorithms that are applied in these contexts (see algorithm below).
First, the Model is updated each time a "session" ends, and so it is only helpful for the next session started by the same user. However, in the museum setting users often use the prediction system once (during a visit to a museum) and might never use it again.
Secondly, a prediction is made by taking into account several m-order Markov models (contexts). The effect of a particular context in a prediction depends on its goodness, i.e., how well it performed for past predictions. In typical settings, the goodness is determined empirically by the creator so as to give out the best performance. However, in our type of application we may eventually encounter many types of users, and the goodness of contexts must be recalculated for each user. Consequently, given that a visitor may change mood/mind while using the system, it is clear that an adaptive run-time algorithm has to be defined to be able to change the prediction parameters dynamically, and not statically as is done in existing PPM algorithms.
By finding solutions to these problems we have developed a highly adaptive model that changes dynamically throughout the visit and does not need to be initialized with information about past uses of the system by the visitor. Initially, when we do not have information about the user, our algorithm gets the first predictions from a system predictor that contains the preferences of all the past users and, as the system acquires more information about the user, it dynamically gives more importance to the user model.
The first problem stated earlier may be easily solved by updating the context array incrementally each time a new event occurs (an artwork is visited). This is done by adding the new event accordingly in the update algorithm and also by modifying the confidence levels accordingly, as we will discuss later. By doing this we have partitioned the updating loop over time so predictions will be always made over the most recent model. If the Model has "m" contexts and there are "n" possible events, then the asymptotic cost of updating the model is O(m*n) .
To solve the second problem, we associate a confidence level to each possible event that can be reached from any other event; that is, the confidence that event "x" having occurred at time "t", the event at time "t+1" could be "y". The confidence levels are of course in the range [0,1] and are initialized at 0.5. These confidence levels are updated each time a new event arrives at the model. Knowing the latest predictions that were made and observing the event that actually takes place the algorithm may apply a corrective measure to the confidence levels of all participating Markov contexts. Contexts that made accurate predictions increase their confidence levels, whereas contexts that were wrong are penalized.
To corroborate the correctness of our method, we will show a trace that demonstrates how the predictions adapt over time to different patterns of preferences. The trace has been performed with models of order 5, i.e. using five Markov contexts that are updated after events of four types of categories occur, and no system model has been used to obtain combined predictions to appreciate in a short time scale the dynamic evolution of the predictors.
The graph in (Figure 4) shows how probabilities assigned to each category evolve with a visit pattern of the form "1111222233334444" where each number represents a different category of explanatory items. As long as a user remains in a given category, the system massively populates this category; the exploration of a different category in a greedy manner makes a prediction that a new category is being explored thoroughly.
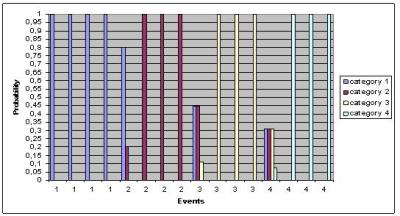
Fig 4: PPM experimental results
Planning Visits with Ant Colony Systems
In our application we also want to find the best subset of artworks to be seen at the museum while not exceeding a time limit set by the visitor. Each artwork takes a given amount of time to see, and there is also a given amount of time spent for moving from one artwork to another. This problem is known as the orienteering problem, where one needs to find a subset of nodes in a weighted graph, with each node having a value and weight, maximizing the sum of values while not exceeding a given weight. In our case the nodes in the graph represent rooms in the museum; the value of each node is the popularity of each room (based on feedback from users); and the weight is the time it takes to visit a room.
In order to solve this problem we have followed an Ant Colony System approach (Liang, 2001). This approach is based on the fact that the behavior of many species of ants is determined by indirect communication mediated by pheromones. While searching for food, ants leave pheromones on the ground forming a trail. It has been shown in many experiments, such as the double bridge experiment (Deneubourg, 1989), that ants follow in a probabilistic manner the paths with stronger concentrations of pheromones which correspond to paths with shorter distances to food places. This natural behavior has been formalized with a simple stochastic model by (Deneubourg, 1989). This model has been the base for solving some minimum cost or graph related problems such as the Traveling Salesman Problem (TSP) or the Orienteering Problem (OP) discussed here.
The ACS is relatively easy to parallelize, in that each node can have a number of ants running independently. At certain synchronization points, the ants exchange information about their pheromone matrices to communicate the results so far.
There has been some previous work in adapting the ACS algorithm for the orienteering problem (Liang, 2001), as well as a parallel approach of the ACS for solving the Traveling Salesman Problem (TSP) (Randall, 2002). We here present an implementation combining these approaches in a parallel implementation of the ACS for the orienteering problem.
In the basic serial algorithm, each ant starts at the given start node, and then selects a new node using one of two transition rules: exploitation or exploration. In the first case the neighbouring node with the highest attractiveness, determined by its distance, weight, score and pheromone trail, is selected. If doing exploration, a random neighbor is chosen, with higher probability given to nodes with higher attractiveness. This process is repeated at each new node until either the new node is the ending node or the available weight limit is exceeded, in which case the ant returns to the ending node. This completes a tour.
An on-line pheromone update rule is applied to each generated tour which evaporates some pheromone to encourage exploration. In addition, after all ants have completed a tour, the best tour is selected and pheromone is added to the edges of this trail, while other edges have some pheromone evaporate. The process is then restarted from the beginning in a new iteration with the updated pheromone matrix.
In our architecture, each node can have one or several ants running, and several nodes can work in parallel. After receiving the starting and ending locations, as well as the time (cost) limit, each node runs the basic serial algorithm locally. After each node has completed a set number of iterations, the best solution is picked and sent to the server for comparison. The server picks the best solution of all the nodes and sends this solution back. Each node applies the offline pheromone update using this globally best solution. The nodes then return to executing the serial version with the updated pheromone matrix. This process repeats until the available execution time is exceeded or a set number of iterations are completed.
We ran a simulation of the algorithm on a standard PC for convenience; this does not affect the results. Figure 5 shows the score obtained after a set number of iterations using a randomly generated graph with 20 nodes, and scores, costs and node distances in the range [0, 100]. We used several runs and averaged the score to obtain the results. It can be observed that increasing the number of ants in the colony (running a fixed number of iterations) contributes to obtaining better solutions (solutions in which the aggregated popularity of the visited artworks increases). Figure 6 shows another run: this time the number of iterations required to find a solution with a minimum given score. A limit of 50 iterations was used to avoid using excessive amounts of time on solutions which had converged to a local optimum. In this case we observe that increasing the number of ants reduces the iterations needed to reach the specified satisfaction level (objective function). This is an important result if we consider a multi-colony implementation where ants can be borrowed from remote nests for a limited amount of time.
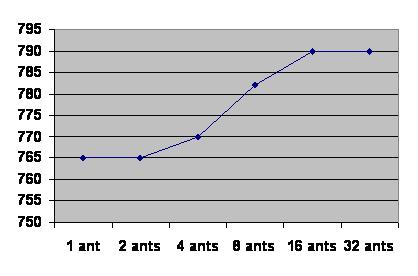
Fig 5: Quality of the solution with varying size of ants
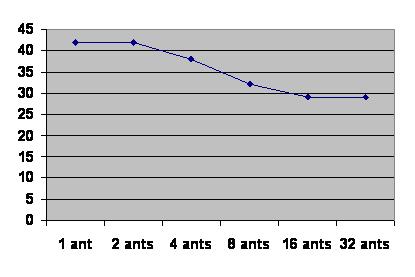
Fig 6: Effectiveness with varying size of ants
In addition to these simulation results, our algorithm has also been used with real museums with underlying graphs having more than 100 nodes obtaining results within seconds. In Figure 7 we show a solution obtained for El Prado museum (the biggest museum in Spain, consisting of three floors). In this picture, popular rooms hosting painters like Velazquez, Goya, Rubens, and others have been marked as red, less popular ones as orange, and very unpopular ones as blue. It can be seen that with the appropriate amount of visiting time the algorithm finds an optimal visiting path in the museum that guarantees that all popular rooms are visited and some less popular ones are also introduced. Therefore, visitors experience a highly rich visit. It is important to note that in the current implementation popularity (obtained by an e-voting system) is the only variable that is used for optimization. In future versions of our algorithm, other weighed metadata associated to artworks could be used. Finally, it is interesting that solutions initially given to the user do not remain static because the user may get ahead or behind schedule during a visit to the museum. To equate visits calculated by ants to the changing timing conditions, we have developed a mechanism of recalculation that is automatically triggered whenever the system detects that the visitor is not following the plan. This is done by measuring the actual time spent between requests to the server and inferring from this information whether the user is extending his visit or not.
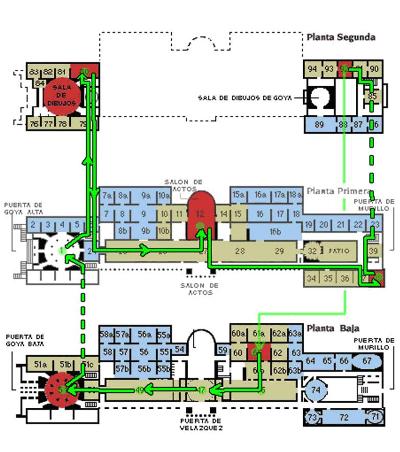
Fig 7: ACS solution at El Prado Museum
Conclusions and Future Research
In this paper we have described MoMo, a Hybrid Museum infrastructure that presents and enhances exhibits using Personal Digital Assistants. We have claimed that existing infrastructures already exist but lack the flexibility to accommodate content to the visitor's taste, do not cope well with large collections of explanatory items, and do not take into account the time available to visitors. Our approach stores the preferences of the user in a stochastic prediction model which is based on high order Markov models. Prediction is performed by partial matching (PPM) algorithms to provide a guess as to the user's preferred contents. Additionally, we also find the best subset of artworks to be seen while not exceeding a time limit. This has been achieved by implementing a distributed Ant Colony System running on PocketPCs, proving that utility computing infrastructures may also be built into mobile devices. Our future research will include the use of our infrastructure in other domains; and the implementation of a generic multi-colony infrastructure for arbitrary mobile devices that takes into account not only artwork's popularity as the optimization variable, but also any other factors that could be relevant in arbitrary domains. This generic infrastructure could be used to solve many optimization problems by using spare computing cycles on mobile devices in a grid-like fashion.
Acknowledgements
We want to express our gratitude to the Microsoft Research Labs for supporting this work under grant "Microsoft Research Excellence Awards for Embedded Systems". We also thank the jury members of the IMAGINE CUP'04, ETI'03, and eMobility'03 for their useful comments, support and awards.
References
Chen, X., X. Zhang (2003). A Popularity-Based Prediction Model for Web Prefetching. IEEE Computer, Vol. 36, No. 3
Deneubourg, J. L., S. Goss, N. Franks, & J.M. Pasteels (1989). The blind leading the blind: modeling chemically mediated army ant raid patterns. J. Insect Behav., 2, 719-725.
Jaen, J and J.H. Canos (2003). A Grid Architecture for Building Hybrid Museums. 2nd International conference on Human.Society@Internet. LNCS 2173. Seoul 2003
Larkin, C. (2004). Renwick Hand Held Education Project. presentation at Museum and the Web 2004. abstract available http://www.archimuse.com/mw2004/abstracts/prg_265000715.html
Liang, Y., A.E. Smith (2001). An Ant Colony Approach to the Orienteering Problem. Submitted to IEEE Transactions on Evolutionary Computation. available http://www.eng.auburn.edu/department/ie/courses/insy7100/OPpaper.pdf
Manning, A., G. Sims (2004). The Blanton iTour, An Interactive Handheld Museum Guide Experiment. In D. Bearman & J. Trant (Eds.) Museum and the Web 2004 Proceedings. Archives & Museum Informatics, 2003. http://www.archimuse.com/mw2004/papers/manning/manning.html.
Marshak, D.S.(2003). J. Paul Getty Museum Re-Architects Technology to Enhance Visitors' Experience. http://www.sun.com/service/about/success/recent/getty.html
Monaci, S. & E. Cigliano, (2003). Multimuseum: a multichannel communication project for the National Museum of Cinema of Turin. In D. Bearman & J. Trant (Eds.) Museum and the Web 2003 Proceedings. Toronto: Archives & Museum Informatics, http://www.archimuse.com/mw2003/papers/monaci/monaci.html
Randall, M. (2002). A Parallel Implementation of Ant Colony. Journal of Parallel and Distributed Computing 62, 1421–1432
Wilson, G. (2004). Multimedia Tour Programme at Tate Modern. In D. Bearman and J. Trant (Eds.) Museums and the Web 2004, Proceedings. Toronto: Archives & Museum Informatics. http://www.archimuse.com/mw2004/papers/wilson/wilson.html
Cite as:
Jaén, J. et al., MoMo: A Hybrid Museum Infrastructure, in J. Trant and D. Bearman (eds.). Museums and the Web 2005: Proceedings, Toronto: Archives & Museum Informatics, published March 31, 2005 at http://www.archimuse.com/mw2005/papers/jaen/jaen.html
April 2005
analytic scripts updated:
October 2010
Telephone: +1 416 691 2516 | Fax: +1 416 352 6025 | E-mail: