
Papers
Reports and analyses from around the world are presented at MW2005.
| Workshops |
| Sessions |
| Speakers |
| Interactions |
| Demonstrations |
| Exhibits |
| Best of the Web |
| produced by
|
| Search A&MI
|
| Join our Mailing List Privacy Policy |
Search Engines and On-line Museum Access on the Web
Teresa Numerico, Jonathan P. Bowen, London South Bank University, United Kingdom and Silvia Filippini-Fantoni, Université Paris I - Sorbonne, France
Abstract
We can consider Web browsing as a similar experience to visiting a museum, when we take decisions about where to stop and where to skip over the exhibited objects. This is the same in museums; there are some tools available to help people select what they want to see such as maps, brochures, etc. Just as in a real museum, where maps and brochures help people organize their visit, search engines support the user in their navigation on the Web by assisting them in finding the most relevant material, while ignoring the rest. The Web is a unique "museum" where there are all sorts of data, including multimedia objects, so it is particularly crucial to respect the potentially different attitudes of users that may have various interests and different perspectives. (This is once again the same in museums.) The role of search engines is particularly problematic because they have to guarantee the efficiency of the service without betraying the multiplicity of users' purposes.
The aim of this paper is to show the result of testing the difficulty of access to useful museum-related resources that are not very well known, but contain relevant information when search engines and other query techniques are used. We will show that many museum Web sites and databases belong to the hidden part of the Web that is not accessible unless the precise URL is known. We will discuss some practical issues on finding museum information and how museums could improve their search rankings and their own searching facilities, especially with respect to the widely used Google search engine.
Further, we will introduce some promising solutions for finding museums' Web sites and searching within them, such as Peer-to-Peer (P2P) search tools, intelligent agents that are specialized for information retrieval using "clustering" strategies based on user preferences, as well as systems of collaborative filtering and collaborative categorization from user experiences and judgments, allowing a personalized search.
All these alternative methods have only a little in common, but share the characteristics of respecting the decentralized and dynamic topology of the Web, while search engines are based on traditional techniques of information retrieval; namely, strategies to access pre-structured data using the appropriate pre-established queries. The Web cannot be compared to a repository of structured data; it requires the development of innovative approaches and methods that take into account its chaotic nature. For all these reasons we do not consider the metadata solution here in detail, despite its role in searching specific museum collections on-line; we believe that there are interesting alternative methods to investigate for the future.
Keywords: search engines, queries, mapping on the Web, the hidden part of the Web
Introduction
Search engines play the role of mediators in accessing information, providing the "guided tours" to visitors by letting them have access to (and also preventing them from accessing) the available on-line content. As in all other surfing experiences, users of museum Web sites are very likely to obtain information on where to look on line via a search engine. This gives an enormous power and a huge responsibility to the companies involved, because they "create" and bias the browsing experience of users by offering a choice of Web sites that is unique for a given search engine, outside of which there is potentially only chaos and incomprehensible noise. The question that arises spontaneously from this premise is: how fair is this Web "guided tour" with regard to museums and exhibitions that are not very well known and not likely to become popular, or with famous museums whose Web sites are not conceived to be retrieved by search engines effectively? Is there no other solution than to use a search engine like Google (http://www.google.com), the most successful search engine at the moment in terms of popularity and commercial achievement (Cusumano, 2005), to look for a museum Web site?
Here we concentrate on search engine technology that does not use metadata (http://www.w3.org/Metadata). This is because we believe that, while it is possible to use metadata effectively in a limited situation like a museum collection covering a particular area, it will far more difficult to scale this up to whole of the Web. This would require on-line librarians to attempt to keep up with the Web's contents, which are both dynamically changing and expanding at an increasingly rapid rate. Simple metadata, such as a title, description and keywords, are possible, and are included in many existing Web pages. However, more complicated metadata is ignored by many existing search engines and is unlikely to be included in a uniform manner across the entire Web. The "Semantic Web" (http://www.w3.org/2001/sw, http://www.semanticWeb.org), proposed by Tim Berners-Lee and others at the World Wide Web Consortium (http://www.w3.org), is likely to be successful in specific areas e.g., XML-based RSS (Really Simple Syndication or RDF Site Summary, http://en.wikipedia.org/wiki/RSS_(protocol)) newsfeeds (Bowen et al., 2003) but universal dispersion across the entire Web will be much harder to achieve.
One approach that can improve searching of the Web is to limit the domain to a particular area of interest. For example, facilities searching for on-line academic publications are improving as there is more collaboration between publishers. See CrossRef (http://www.crossref.org) that is using Digital Object Identifiers (DOI, http://en.wikipedia.org/wiki/Digital_object_identifier) to identify articles as part of their metadata in a similar manner to Universal Resource Locators (URL, http://en.wikipedia.org/wiki/URL) for Web resources, to which DOIs can easily be resolved (http://dx.doi.org). Google (http://www.google.com) is now providing searching of academic papers in a similar but more specialized manner to its more general Web search facilities (http://scholar.google.com). It is also providing other specialized facilities such as searching of individual personal computers (http://desktop.google.com).
An alternative more general solution to help with the problem of retrieving important information on the Web is to use one or more "metasearch" engines (http://en.wikipedia.org/wiki/Metasearch_engine), tools that do not maintain their own repository of Web pages, but rather compare the search of various engines, removing any duplicate pages. See, for example, Vivisimo (http://vivisimo.com), which clusters results into categories so that it is easier to browse them), Ixquick (http://www.ixquick.com), Metacrawler (http://www.metacrawler.com) and Dogpile (http://www.dogpile.com), although beware of the lack of separation between paying Web sites and high ranking results for these last two sites. There are also tools that offer some deeper search capabilities such as Surfwax (http://www.surfwax.com) or Copernic (http://www.copernic.com), which must be downloaded and installed, but the basic version is free. More information about metasearch engines is available elsewhere (http://www.lib.berkeley.edu/TeachingLib/Guides/Internet/MetaSearch.html).
For those wishing to find out more about search engine design from a technical standpoint, see Arasu et al. (2001). For on-line search engine information, see SearchEngineWatch (http://www.searchenginewatch.com) and articles with some additional links from Wikipedia (http://en.wikipedia.org/wiki/Search_engine) and Webopedia (http://www.Webopedia.com/DidYouKnow/Internet/2003/HowWebSearchEnginesWork.asp). ResearchBuzz (http://www.researchbuzz.com) includes news and information about search engines. Many further Web links on searching the Internet can be found in the Google Directory (http://directory.google.com/Top/Computers/Internet/Searching).
In this paper we first consider the background to the current situation from a philosophical standpoint and the problems that can be encountered because of the disorganized nature of the Web and the lack of universal semantic content. We consider practical aspects of searching with the Google search engine, including some specific case study examples illustrating some of the issues of using search engines in a museum context. We also cover some practical issues in gaining a better search engine ranking for museum Web sites. After discussing the problems of metadata, we finish with consideration of future developments: the use of personalization facilities in searching Web (Bowen & Filippini-Fantoni, 2004), "push" technology and how search technology could develop using the Peer-to-Peer approach, followed by a short conclusion. If desired, and depending of the interests of the reader, these various aspects can be read separately.
Background
The Web can be considered as a potential source of all our knowledge, but viewed in this perspective it has some disadvantages. The main limitation is that the Web is a kind of enormous Borgesian Library of Babel, a modern labyrinth where we can remain trapped in peripheral or even in central areas, because of the huge overload of information accessible and the general chaos of its organization.
The universe (which others call the Library) is composed of an indefinite and perhaps infinite number of hexagonal galleries, with vast air shafts between, surrounded by very low railings. From any of the hexagons one can see, interminably, the upper and lower floors. The distribution of the galleries is invariable. Twenty shelves, five long shelves per side, cover all the sides except two; their height, which is the distance from floor to ceiling, scarcely exceeds that of a normal bookcase. One of the free sides leads to a narrow hallway which opens onto another gallery, identical to the first and to all the rest. To the left and right of the hallway there are two very small closets. In the first, one may sleep standing up; in the other, satisfy one's fecal necessities. Also through here passes a spiral stairway, which sinks abysmally and soars upwards to remote distances. In the hallway there is a mirror which faithfully duplicates all appearances. Men usually infer from this mirror that the Library is not infinite (if it were, why this illusory duplication?); I prefer to dream that its polished surfaces represent and promise the infinite ... Light is provided by some spherical fruit which bear the name of lamps. There are two, transversally placed, in each hexagon. The light they emit is insufficient, incessant (Borges, 1941).
The experience of the labyrinth described by this short novel gives a very good flavor of the emotions that users have when they face the so-called "navigation problem": they feel lost and sometimes trapped in cyberspace because they do not know where they are, what the context of the piece of information that they are reading is, where to go next in order to pursue the process they have started to acquire the right information, and how to go back to the pages they have already visited (Nielsen, 1990; Levene & Wheeldon, 2002).
Many users feel powerless with respect to the complexity of information available. So the only possible way to avoid chaos is to rely on search engine "intelligence" to correctly interpret their queries, adequately represent the Webs resources and efficiently communicate the relevant results available on-line. However we must be careful because of the key filter role represented by search engines, giving a unique interface with the entire Babel/Web library.
The key role of creating an index of Web documents, if perceived as the world's archives, is a critical and sensitive one. In order to explain this role, we consider the insightful interpretation of the archive and archivists' importance in society made by the 20th century philosopher Jacques Derrida, who died in 2004. The term archive is related to the Greek word arkhē, which has two meanings: commencement and commandment. An "archive" keeps both these senses in its meaning, because it is related to the memory and cultural heritage of a people, as well as a catalogue providing an index by which all these memories can be consulted in a useful way by people in the future. Archivists and museum curators perform very powerful roles viewed from this perspective. According to Derrida:
They do not only ensure the physical security of what is deposited and of the substrate. They are also accorded the hermeneutic right and competence. They have the power to interpret the archives. (Derrida (1996: 2)
If we accept that all the relevant documents for the memory of all the people in the world could be kept on the Web, then those who create the index and the repository to make it all accessible hold huge power. Such considerations are not well understood by the general public, but experts in cultural heritage and museum curators should be more aware of such issues. Moreover, due to their traditional area of expertise, they should be in a good position to contribute to the debate, offering potentially interesting solutions to the problem not only with regards to their specific domain of interest, such as the conservation and the exploitation of cultural heritage documents and objects, but also more generally with respect to knowledge management. This is why we believe that museum professionals provide an important readership for the subject matter in this paper.
In summary, search engines are the only really viable solution to navigation problems on the Web, but unfortunately they have some limitations. Let us now go more deeply into the details of the difficulties encountered by someone trying to access the Web for the purpose of retrieving useful material, and see the possible remedies that can be built in order to remove the obstacles.
Search Engine Limitations
All search engines are necessarily partial in their choice of resources presented to the user for a number of different reasons. For example:
- There is a time limit in the capabilities of crawlers (the intelligent software agents that explore the Web to keep track, catalogue and classify Web sites). They take time to explore the Internet and the growth of the Web is around 7.5 million new documents per day; this means that the view presented by search engines can never be completely up to date.
- There is a language problem; most of the catalogued resources are in English, but there are huge amounts of resources in other languages. Search engines tent to privilege English language resources because they dominate the Web.
- The standard search engines are text based and not image, sound or video based; it is difficult to catalogue the resources based on other media, although there are some initial efforts in this direction.
- Search engines catalogue HTML (HyperText Markup Language, http://www.w3.org/MarkUp) pages, not databases, or other structured type of data or dynamic pages, unless a hyperlink is created directly to the resource. For example search engines do not include their own pages dynamically generated by users' queries in their results.
- Search engines use a partial representation of the Web, using a particular algorithm, like PageRank for Google (http://www.google.com/technology), a proprietary cataloguing method. E.g., special relevance may be given to metadata tags, to titles or to other elements of the page.
- The legitimate commercial attitude of most search engines or directories means that they attribute a high rank to paying resources potentially independently of their content weight
- Due to the enormous amount of data available, there are so many results for each query that it is impossible to scroll all of them, so the real results are only the resources sorted on top of the output, or at least in the first two or three pages.
Moreover considering the nature of the Web, we share the worries raised by Lawrence & Giles (1998) that are still very relevant:
The Web is a distributed dynamic and rapidly growing information resource, which presents difficulties for traditional information technologies. Traditional information retrieval systems were designed for different environments and have typically being used for indexing a static collection of directly accessible documents. The nature of the Web brings up important questions as to whether the centralized architecture of the search engines can keep up with the expanding number of documents, and if they can regularly update their databases to detect modified, deleted and relocated information. The answers to these questions impact on the best search methodology to use when searching the Web and on the future of Web search technology (Lawrence & Giles, 1998).
The experiment that they made was supposed to measure comparatively the quality of search engines results, but they discovered that they could also estimate the size of the entire Web on the basis of an analysis of the overlap among the engines, without taking into account the invisible Web (see later for more details). Though it was very difficult to obtain a definite result, they concluded that even the best search engine at that time, HotBot (http://www.hotbot.com), did not cover more than 34% of the entire Web (Lawrence & Giles, 1998). They repeated the experiment a year later (Barabási, 2002: 164) but though there was a change in the comparative performances of search engines, and Google was taking over HotBot, there was not a better result in terms of absolute coverage of the Web. There are various practical problems that can cause this lack of precision in results by search engines, such as the technique used to retrieve information, the fact that the documents searched may not exist any longer or they may have changed their position on the Web so they are not accessible at the previous address, etc.
Therefore we are in the undesirable situation in which we have the illusion that we can access all the available resources, while in practice we have admittance only to a small amount of them. There is a risk that many people might not be aware of the problem. It is as if Web users can enter the biggest library in the world, where there are all the books, photographs, music, films ever produced are available, but some of the librarians have used various incoherent cataloguing styles. Some of the librarians even changed the position of many of the resources on the shelves, so they do not correspond to the catalogued descriptions. Some other librarians are involved in powerful commercial interests and catalogue only resources of interest to their sponsors. It is then very difficult to achieve a correct correspondence between titles, authors, subjects and shelf marks of the resources. There are exceptions consisting of the catalogues created before the librarians became overwhelmed. We can benefit only from those small parts of the catalogues, but very often it is impossible to distinguish between correct and corrupted catalogues.
Web Topology
In order to understand thoroughly the problems implied in searching information on the Web, it is inadvisable to concentrate only on the limits of the algorithms used by the various search engines; these practical limitations are only part of the issue discussed here. There is another key element that must be taken into account to provide a clear understanding of the problem, namely the topology of the network. As a consequence of the fact that Web hyperlinks are unidirectional, it is possible to travel with ease only one way when following links. If two nodes (Web pages) are not connected directly you can connect them through other nodes, but in a directed network there is no guarantee that you can follow an inverse path (Barabási, 2002: 167). The directedness has some consequences for the networks topology, effects that were discovered by a group of researchers from AltaVista, IBM and Compaq when they did some experiments on the topology of the Web (Broder et al., 2000). They discovered that the structure of the Web has the characteristic form of a "bowtie" (Kumar et al., 2002; see Fig.1).
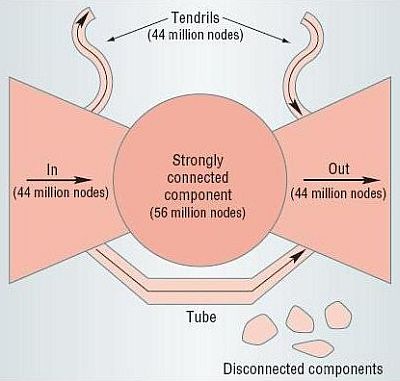
Fig1: Characteristic "bowtie" structure of the Web (Kumar et al., 2002).
The network appears to be divided into four main different "continents" that are only partially connected with each other. Except for the central core that is the central area of the Web in which all the nodes are reachable on average in about two links from any other node in the same area, all the other continent are fragmented and some even isolated from the rest of the network, as is clearly visible from Fig. 1. These continents will always be the topological structure of any directed network as was shown by a team of researchers from Portugal (Dorogovtsev et al., 2001). Search engine repositories rely on the work of Web crawlers, software agents that surf the Web, traversing from one link to the next, so they cannot access Web pages that are not connected to the rest of the Web through links (or explicitly submitted to them by users), and these areas remain unexplored and hidden from the search engines, increasing the deep or invisible Web. As admitted also by Monika Henzinger, a manager of Google research team, there are still open problems to solve in the area of researching information on the Web:
However, there are still many open problems and areas for future research. [ ] The problem of uniformly sampling the Web is still open in practice: which pages should be counted, and how can we reduce biases? Web growth models approximate the true nature of how the Web grows: how can the current models be refined to improve accuracy, while keeping the models relatively simple and easy to understand and analyze? Finally, community identification remains an open area: how can the accuracy of community identification be improved, and how can communities be best structured or presented to account for differences of opinion in what is considered a community? (Henzinger & Giles, 2004: 5190).
Some of the problems mentioned in this passage have already been discussed, but there is one that deserves some attention: the community identification issue, as important in the context of museums as any other (Beler et al., 2004). We can consider museum Web sites as a kind of community, in which each Web site gives its own contribution to the general content of cultural or scientific heritage and history. The possibility of identifying this community would grant extra visibility to any single museum Web site within the group. A Web page describing the content of a small museum can easily attract only a little or even no visibility on the Web, but if it is linked to a community of museum Web sites, the well-known museums can improve its presence on the Web, helping small institutions to become better known. In this sense, owners of museum Web sites should not consider the other similar pages as competitors, but as opportunities of obtaining extra visibility and new potential audiences.
Another relevant and inevitable issue for search engines is the definition of a balanced performance, both in terms of coverage and of freshness; it is very difficult to have a large repository and also to refresh the pages in a timely manner, in order to guarantee keeping up to date with the frequent refresh rate of some pages. RSS newsfeeds have been designed to address this problem in a limited way for frequently updated news articles on the Web (Bowen et al., 2003). See, for example, the Museophile museum discussions forums Web site (http://forums.museophile.net) for a collection of regularly updated museum-related newsfeeds.
The Invisible Web
In any case, as we suggested before, there is a huge area of the Web that remains invisible and closed to crawlers because of different reasons (technical limitations, deliberate choice of crawlers, etc.). This means that there is a large part of the Web that is not accessed by crawlers, and it can contain high quality information. Which is the information that is not available to crawlers but is theoretically accessible on the Web? The answer to this question can be found in an interesting book on the invisible Web (Sherman & Price, 2001: chapter 4, http://www.invisible-Web.net). Some of the categories of invisible Web pages can be found on museum Web sites. There are various types of pages that crawlers are not able to surf due to the invisible Web, such as:
- sites that contain forms that need to be filled out in order to access the real Web site;
- dynamically generated pages that contain inaccessible technologies such as Flash or other multimedia formats with no text equivalent;
- pages offering real-time data;
- documents in non-HTML formats (although Google is able to archive PDF format documents, for example);
- pages that give access to a database, even if they are provided with an HTML Web interface, where in order to access the data, it is necessary to insert a query and crawlers are not able to interact with such a complex interface.
Keeping this analysis in mind, we now discuss what is widely considered to be the most effective Web search engine at the moment, Google, investigating the characteristics that have made it so successful. We also consider the risk that this technology inevitably represents for a democratic diffusion of information, particularly for weak or non-commercial institutions.
The Google Search Engine
In this section, we concentrate on Google (http://www.google.com), which is the most successful search engine so far, trying to understand the reasons for its power in retrieving data on the Web. It is well-known that its efficiency depends, beyond the huge number of indexed pages, mainly on its search algorithm, PageRank, which is based on the exploitation of interconnections of Web pages as a way to attribute authority to pages. According to a recent (10 November 2004) estimate of the Google technical team, there are almost 8 billion pages indexed in the repository (http://www.google.com/googleblog/2004/11/googles-index-nearly-doubles.html). The PageRank algorithm mixes a standard inverted index of all pages, treated as vectors of strings, with a system that allows it to attribute authority to a page according to the links that it receives from other pages. A link from page "A" to page "B" is interpreted as a "mark" given to the "B" page from the "A" page. The value of the link depends also on the authority of "A".
So the success of Google is related to its capability of taking into account the real topology of the Web when creating the ranking for the pages (Brin & Page, 1998). Pages linked by many authoritative pages have more credentials to be considered relevant for the users. This capitalizes on human knowledge and expertise since most links on the Web have been inserted by a human being. However, even if the system works well when looking for hubs and "mainstream" pages, Google's results are less trustworthy when searching for "minority pages". When we seek information that is not very well known, or not very popular, or even only written in a language that is not widely spoken, like Italian for example, it is much more difficult to find (Cho & Roy, 2004). Though minorities' protection is not typically at the center of the users' attention, it is a very relevant issue in the perspective of the creation of the ecology of the Web as a collective and distributed information tool. Thus the ranking mechanism that is the main reason for the "fitness" of Google performance produces at the same time discrimination against all sorts of minorities present on the Web (language minorities, scientific minorities, newly formed communities, small local specialist museums, etc.).
Minorities' visibility is not the only problem that we encounter when we use Google as our main front door to access the Web; there is also the "Google bombing" phenomenon (http://en.wikipedia.org/wiki/Google_bomb). As an example, try typing the string "miserable failure" into the Google query box and the first result obtained is President Bush's Web page on the White House Web site (http://www.whitehouse.gov/president/gwbbio.html). This is the outcome of the exploitation of PageRank algorithm characteristics by a group of hackers. To achieve this result they did not need to alter the target page. They only needed to create a network of pages, widely cross-linked with each other, using that term and linked to the Bush homepage. Notice that this activity is perfectly legal. And it is not an isolated episode; all commercial companies can make the most of it to increase the rankings of their homepages relative to the desired keywords (Gori & Numerico, 2003). Museum Web sites could easily be obscured by commercial enterprises wishing to sell artworks, for example. The risk is that instead of obtaining, at the top of the list, results relevant to cultural heritage and historical information provided by museums, we could obtain fake artistic or cultural Web pages whose aim is entirely commercial.
Google includes more advanced search features (http://www.google.com/advanced_search), including options such as language, file format (PDF, PostScript, Word, etc., as well as HTML), date of last page update, location of text to be searched (e.g., limited to the title, page text, URL or even links to the page), limited to a particular Internet domain address, etc. It is also possible to search for similar pages or pages that link to a Web site (e.g., to see if reciprocal links are appropriate from your museum's Web site). This can be done directly by adding "link:" in front of a URL within a Google search string (e.g., http://www.google.com/search?q=link:vlmp.museophile.org). However, for most simple queries these additional facilities are not needed. For further information on searching using Google, see Google's on-line help information (http://www.google.com/help). Calishain & Dornfest (2004) provide more detailed information, including technical information on incorporating Google searching into a Web site.
Next we consider three case studies in the use of Google for searching in the context of finding museum information on-line. The first considers general issues and how they could apply to on-line museum information. The others give examples of problems when searching for information on-line.
Case Study 1: Google Vs. Experts
On Friday 11 February 2005, The Gadget Show, on Channel 5 UK television, held a not very scientific but illustrative quiz between a person using Google and a four-person team of experts. There were four questions, each demonstrating the pros and cons of naive use of Google in searching for information.
The first question asked for the value of the mathematical constant π to nine decimal places. The experts could only manage seven decimal places. On typing "pi" into Google (http://www.google.com/search?q=pi), the Google calculator (http://www.google.com/help/features.html#calculator) gives π to eight decimal places instantly: 3.14159265. The π Pages (http://www.cecm.sfu.ca/pi/pi.html), listed first by Google (although note that Google search lists will vary with time as the Web changes), include a Java applet that speaks the value of π (in French by default) continuously as well as displaying the numerical values. This was enough to give the correct answer, assuming that Java is working correctly on the user's client computer. This is not always the case, so the pages could be made more accessible for these without the necessary technology. Interestingly, none of the top nine Google returns included the actual (approximate) value of π in the short entries listed by Google and the tenth one only gave the value 3.14 since this has been dubbed "National Pi Day" (14 March). This illustrates the importance of including the most critical information in a Web site's listing in Google. A museum's home page should include keywords that are critical and relevant to its mission.
The second question asked for the age of the (British) Queen. This of course is a moving value and a number of out-of-date Web pages were found by Google giving the incorrect answer. The "experts" were similarly unsure. Of course, the users of Google could have searched for the Queen's birthday, a fixed value, and then calculated her age, but even this is problematic since the Queen has an official birthday and an actual birthday. Thus the combination of some background knowledge with the use of Google could have resulted in the correct answer. The use of quotation marks when querying Google could also have helped here, together with knowledge that her name is "Queen Elizabeth II". Searching for "age of Queen Elizabeth II" (http://www.google.com/search?q=age+of+Queen+Elizabeth+II) was not a very successful strategy since the individual words can appear in any order anywhere on the Web page for Google to consider that a match has been found. Note that "of" is considered a common word by Google and is ignored anyway.
Searching for "Queen Elizabeth II" age (http://www.google.com/search?q="Queen+Elizabeth+II"+age) is a more successful strategy since the phrase "Queen Elizabeth II" must be exactly in that form for a search match to be found. In this case, the third entry (http://www.deadoraliveinfo.com/dead.nsf/enames-nf/Elizabeth+Queen+II) returned included the string "Date of Birth: Current Age: 04/21/1926 78" within the Google page itself, giving the correct answer and the date of birth as well by way of confirmation. Note that searching for the completely quoted string "age of Queen Elizabeth II" (http://www.google.com/search?q="age+of+Queen+Elizabeth+II") is not a good strategy. This only returned a single not very helpful Web page on murals of the 1950s (http://beechcourtgardens.co.uk/church/murals.htm). A good strategy when using Google to search for terms for research purposes is to quote individual phrases of words that should be together and to include more that one quoted phrase if necessary, rather than quoting longer phrases since this is likely to limit the search too much.
As a general lesson, it is also a good idea either not to include information that will date quickly on a museum Web site or to ensure that the information is maintained and updated very regularly. Suitable management structures, not to mention enthusiasm of the relevant museum personnel, need to be in place for this to be done effectively.
The third question requested the national flower of Turkey. Again, a naive search for "national flower of Turkey" (http://www.google.com/search?q=national+flower+of+Turkey) returns many commercial flower shop Web sites. In this case the experts could answer the question, but the Google searcher in the television program could not, although the answer (the tulip) can be found in the second link from the Google query above (http://www.sunsearch.info/alanya/english/sights/?profile_id=67). Perhaps the Google user entered a different search phrase or the Web sites listed by Google have changed. In any case, by quoting the phrase "national flower of Turkey" (i.e., by insisting that this phrase appears exactly in this form), a much better set of pages is returned (http://www.google.com/search?q="national+flower+of+Turkey"), with the answer included in nine out of the top ten sites within the Google listing itself.
Finally three out of the four experts (and Google) were asked where the fourth member of the team used to work in Geneva. They did not know, but since he was an academic with much on-line material about him available, a Google search of his name together with "Geneva" was enough to reveal the answer very quickly. Searching for information on academics is often a very fruitful line of research, but searching for commercial contacts may be more difficult because companies are much more secretive about their employees. Museum personnel are often much more hidden on-line than most academics, but they may be more accessible than employees in industry.
Many commercial Web sites are very impersonal, and it is difficult to contact real people through them. There are well-known examples with respect to this, which can cause customer relations difficulties in the case of disputes. Academic Web sites often contain much personal research material; museums form a halfway house between the academic, and commercial extremes and the amount of information found on its personnel will depend on the nature of the museum. The larger, more academic ones tend to have more information. It is recommended that museums include some form of contact information on their Web sites, although one should be careful about the inclusion of e-mail addresses. These will be found by spam e-mail "spiders" that are generating e-mail address lists for unscrupulous sale and use, as well as by legitimate search engines. There are technical tricks to avoid problems such as generation of e-mail addresses using HTML character encoding, JavaScript or the use of images (http://javascript.about.com/library/blemail1.htm).
In summary, a very important technique when using search engines in general and Google in particular is to add double quote marks around groups of words that you wish to appear together in the documents to be returned. This can improve the quality of ordering of pages that are listed significantly if done with care.
Case Study 2: Searching For Italian Art
The non-expert user faces difficulties when trying to find something on the Web in a field in which they are not knowledgeable. Suppose that we are in a situation of being young American students with some basic knowledge of Italian who wants to investigate art museums. They do not want to know about Italian museums in particular, but they are interested in art in general. They know that Italy is the most important country for the Renaissance period since much of the relevant Renaissance art can be found in Italy.
We hypothesize that they are proud of their knowledge of Italian, and will pose an Italian query "museo arte moderna" (http://www.google.com/search?q=museo+arte+moderna), meaning "Renaissance art museum". What they are presented with as the first page of results using Google is not a good selection at the time of writing: only three Italian museums, one from Bozen (http://www.museion.it), another from Trento twice (http://www.mart.tn.it), and a third from Anticoli Corrado (http://www.anticoli-corrado.it/Museo.htm) - all not among the most relevant Italian museums of modern art; MOMA (http://www.moma.org) as the first entry and as another entry the Museo d'Art Moderna in Lugano, Switzerland (http://www.museodartemoderna-lugano.ch/; also the MUMOK in Vienna, Austria (http://www.mumok.at), the San Francisco Museum of Modern Art (http://www.sfmoma.org), and Museos en México from Artes e Historia México (http://www.arts-history.mx).
On the second page the situation is no better: we have only 4 entries out of ten for Italian museums and again they are only secondary museums, compared to the Roman, Florentine and Venetian Museums. Moreover there is a major misunderstanding here, because in Italian "Arte Moderna" means Renaissance art (from the 15th to the 18th century) while in English "Modern Art" normally refers to 20th century art (traditionally post Cézanne); so not only was it not possible to find the important Italian museums, but there was also a misinterpretation of the meaning of the Italian query. There was no mention of the most important Renaissance art museums such as the Musei Vaticani (http://mv.vatican.va/StartNew_IT.html), the Uffizi (http://www.uffizi.firenze.it), the Pinacoteca di Brera in Milan (http://www.brera.beniculturali.it), the Museo di Capodimonte in Naples (http://www.musis.it/capodimonte.asp?museo=1), the Gallerie dell'Accademia in Venice (http://www.gallerieaccademia.org), or even of some of the most important museums of Renaissance art such as the Louvre (http://www.louvre.fr) or the National Gallery in London (http://www.nationalgallery.org.uk).
The situation is no better if instead of the Italian expression we use the string "Renaissance art museum". We get two entries from the early Web site, the Web Museum (http://www.ibiblio.org/wm/paint/glo/renaissance), two from another Web site called Art History (http://witcombe.sbc.edu/ARTH16thcentury.html) a Web site about the Pope (http://www.christusrex.org) from which you can reach the Vatican Museum's Web site directly, a private collection of links about Renaissance art (http://www.providence.edu/dwc/Renart.htm), plus three other US museums. The situation is no better if you use the language preferences to select only Web pages written in Italian: using the string "museo arte contemporanea" (http://www.google.com/search?q=museo+arte+contemporanea), you get pages written in Italian but not necessarily related to the most relevant Italian museums, together with some pages related to US or Switzerland museums, and even a commercial Italian publishing house specializing in museum catalogues (http://www.mazzotta.it).
This is just a quick example to illustrate the situation. The ordering algorithm of Google favors highly linked Web pages; English language museums have more citations since they are also linked from many Web sites, including non-English language ones, and so receive a better ranking. An additional problem is that the query string could match for a number of different languages and Italian is not a widely used language, so there is possible confusion with Spanish and German museum Web sites as well. It is also likely that Web sites of Italian museums could not compete in terms of organization of information with other countrys cultural institutions. In summary, the results obtained by investigating on Google about modern art museums using Italian were quite misleading with respect to the reality. This case study is just to illustrate that you should not rely on one search engine, particularly if you are exploring an area in which you are not an expert. It is very important to have different resources to explore the Web in order to obtain better information about what is available on-line.
However, we have to underline the inadequate attitude of Italian museums since they do not seem to undertake relevant promotional activity on the Internet effectively. For example, the Uffizi has allowed their obvious Web address (http://www.uffizi.it) to be used by a company that sells art objects, and offers all sort of different services, including information technology projects. The same is true for the Vatican that has allowed an obvious Italian domain name (http://www.vaticano.it) to be used by a private citizen who is producing and selling elastic Webbings for furniture. An obvious address for the Vatican museums (http://www.museivaticani.it) is forwarded to an alternative commercial Web location (http://www.alberghi.com ) offering accommodation in hotel rooms in different cities around the world. Even if the Vatican museums use ".va" as a top-level domain name, they could take more action to ensure that related Web addresses redirect visitors to their main URL, although to be fair a number of Web addresses do redirect appropriately (e.g., http://www.vatican.it, http://www.vatican.net, http://www.vatican.edu). The Web site of the Vatican museums is created as a subsection of the general Web site on the Vatican (http://www.vatican.va) and even their top-level domain (http://mv.vatican.va) does not redirect users to the main Musei Vaticani Web page correctly, but rather to the main Vatican Web page instead.
The lack of interest of Italian museums in the Web can also be seen with regard to Venetian museums, many of which still do not even own their Web site. They are collected together in the general Web site of the civic museums of Venice (http://www.museiciviciveneziani.it). In this Web site you can find a lot of information about museums as important as the Doge's Palace, Museo Correr, Ca' Rezzonico, Ca' Pesaro, etc., but the user has to know how to navigate the Web site effectively. For example, a database of objects contained in each museum is accessible, searchable by different categories, but the section (http://www.museiciviciveneziani.it/frame.asp?sezione=collezioni) is hidden as a sub-menu within the "research services" menu.
Even if Google can be seen as not favoring Italian Web sites, due to the structure of its ranking algorithm, Italian museum Webmasters could do better in improving the ranking for their Web sites in search engines, in order to allow on-line visitors to understand the quantity and quality of important artworks that are available in their collections.
Case Study 3: Searching For Renoir's Paintings
In this section, as a case study, we will describe the situation which many museum curators or art students might encounter in trying to locate useful material for an exhibition or research. One of the authors is currently working on the Web site for an exhibition on Renoir and Cézanne's paintings (http://www.cezannerenoir.it) from the Guillaume's collection of the Orangerie Museum in Paris (which still appears to have no official Web site!), opening at the Accademia Carrara, Bergamo, Italy (http://www.accademiacarrara.bergamo.it).
We first prepared an "under construction" page with the registered domain and a few basic pieces of information about the exhibition, including the title, a brief description of the content of the exhibition, a few pictures and practical information. We did not put any effort into referencing it through external links and search engines because it was only meant to be a temporary solution. Thus it became part of that invisible Web as mentioned earlier since no search engine was able to reference it, even through a very specific search like "Accademia Carrara Renoir Cezanne" (http://www.google.com/search?q="Accademia+Carrara"+Renoir+Cezanne). That gave access to all sort of on-line articles about the exhibition but not to the exhibition Web site itself.
During the preparation of the Web site, there was a need to make a list of the most important museums that included Renoir's paintings in their collections so that they could be referenced on the Web site. We started by looking for the word "Renoir" on Google (http://www.google.com/search?q=Renoir). There was a list of on-line material on the painter but no trace of a museum Web site till the end of the second page, where the first one to appear was the Phillips collection's Web site in Washington DC, which holds one of the most beautiful and popular paintings by the artist: "Le déjeuner des canotiers" (Luncheon of the Boating Party, http://www.phillipscollection.org/html/lbp.html), followed only at the end of the third page, by the Web site of an exhibition on Renoir and other artists from the Collection Guillaume (http://www.ngv.vic.gov.au/orangerie), very similar to the one the Accademia Carrara was organizing, a Web site that we had accessed many times before during the preparation of our own Web site and that, considering our interest in it, should have appeared at the top of the list (see the section on personalization later). Exploring the other search result's pages, there was only a trace of a few other museums, including the Getty (http://www.getty.edu) in Los Angeles, but no evidence whatsoever of museums like the Musée d'Orsay (http://www.musee-orsay.fr) in Paris or the State Hermitage Museum (http://www.hermitagemuseum.org) in St. Petersburg, which holds many exemplars of Renoir's paintings and whose Web sites are fully available in English.
Unhappy with the results, we decided to make the search more specific and look for "Renoir museum" (http://www.google.com/search?q=Renoir+museum). The results were no better, as this listed, besides the reference at number one to a "brochureware" Web site for Renoir museum that is an estate which belonged to the artist (http://www.riviera-magazine.com/tourisme/cagnes/MuseeRenoir-us.html), once again the Web site of the Phillips collection, and on the second page, the Getty Museum (http://www.getty.edu/art/collections/bio/a620-1.html), the San Diego Museum of Art (http://www.sdmart.org/exhibition-renoir.html) and the Museum of Fine Arts (http://www.mfa.org/artemis/results.asp?am=renoir) in Boston. In between these Web sites there were a number of articles that make reference to museum exhibitions or collections but were not the museum Web site themselves (e.g., see the Google Directory entry, http://directory.google.com/Top/Arts/Art_History/Artists/R/Renoir,_Pierre_Auguste). The results did not help much because it only added a couple of museums to the list, and mostly minor museums that only had one or two paintings by the artist. There was still no trace of the Musée d'Orsay or the Hermitage. It was also strange that there were no other French museums, since we knew that, as well as the Musée d'Orsay, the Louvre, the Musée de Grenoble (http://www.museedegrenoble.fr) and the Musée de l'Orangerie had works of art by the French impressionist artist.
So we decided to search for results using "Renoir" (http://www.google.com/search?hl=fr&q=Renoir) and "Renoir musée" (http://www.google.com/search?hl=fr&q=Renoir+musée) in French pages only. However, here once again the results were very disappointing. No museum Web page seemed to appear in the first pages of search results for "Renoir" (http://www.google.com/search?q=Renoir) while for "Renoir museum" (http://www.google.com/search?q=Renoir+museum), the first museum to appear on the list (seventh position) was the Musée Marmottan (http://www.marmottan.com), followed in ninth position by the Musée des beaux-arts du Canada (National Gallery of Canada, Ottawa, http://national.gallery.ca). Finally at page two (with the default ten items on each set of Google search results), there is a link to a page of the Musée d'Orsay, which unfortunately only led to an empty page in the Spanish version of the site with the name Renoir on it!
At this point we were curious to find out what resources were available on the Musée d'Orsay Web site for Renoir and we specified the search (by limiting it to French pages) even further by looking for "Renoir Orsay" (http://www.google.com/search?hl=fr&q=Renoir+Orsay) and surprisingly enough the Musée dOrsay Web site was only fourth in the list of Google results, preceded by other irrelevant material. If not limited to the French page, for the same query (http://www.google.com/search?q=Renoir+Orsay), the museum Web site would only have appeared on the third page of Google results.
As for the State Hermitage Museum in St. Petersburg, we were also quite surprised that no search results gave access to Renoir material from the museum's Web site, knowing that it had about 21 paintings from this artist. So we refined the search query for "Renoir Hermitage" (http://www.google.com/search?q=Renoir+Hermitage) and once again we were surprised by the result. The first two results were from the Guggenheim Hermitage Museum in Las Vegas, which apparently hold two portraits of the artist, followed by a link to a Danish Web site with information about the Hermitage Museum and its collection. The Hermitage Web site itself only ranked fourth; however, this was not with a list of works of art by the artist but with a link to a page of a special exhibition they had held on him. If I wanted to have access to a list of works of art by Renoir available in the museum, I would have to go on the Hermitage museum Web site and look for them in the collection's database. Only by doing a database search on Renoir would I have had access to a list of 21 paintings. This is a typical example of the problem of the invisible Web as mentioned earlier since there are no direct links to the information in the museum's database for the search engine Web crawlers to find.
After facing all these difficulties, we finally decided to give up and resort to the old fashion method of looking for information in a book. In the library there was a book on Renoir that had a list of works of art from the many museums around the world.
Later, an art historian colleague mentioned the Web site Artcyclopedia (http://www.artcyclopedia.com) that includes lists of paintings by artists including Renoir (http://www.artcyclopedia.com/artists/renoir_pierre-auguste.html). In fact it was exactly what was required in this particular situation, but it was not found by Google in the searches that were made, or it least it was not spotted among the many sites returned as being good sites for the purpose of this research. Overall, this case study illustrates that even large museums have very little direct visibility on the Web through search engines like Google when it comes to detailed content of their collections. In the next section, we consider a few simple techniques that can help to alleviate the situation.
Improving Your Search Engine Ranking
Museums are not as proactive in ensuring they rank well on Google as many of their commercial counterparts. However there are some basic tactics that are worthwhile, and that do not require great financial cost to implement. Google's PageRank algorithm uses both links to and links from a Web site to determine its position when returned from a giving search query. It is a good idea to encourage links to your museums Web site and also to be generous in including links from your museum to related resources. These can be mutually reinforcing since sites with links to other Web sites ("portals") naturally attract links to them.
To find sites for possible cross-linking, it is worthwhile entering keywords relevant for your site into Google itself, requesting that highly rated sites link to you, and adding links to these sites from your own museum Web site. The sites that are found will naturally have a high Google ranking already, and links to and from these will help to increase your own site's rating on Google. A personal message (e.g., via email) illustrating that you have actually looked at the Web site properly and appreciate the content is usually best. Nothing can guarantee a cross-link back to your own site, although having good on-line content yourself (which most museums can provide with some effort) is likely to encourage this. More altruistically, linking to other lesser known but related museum Web sites will help those sites and ultimately your own site as these become more highly rated. Forming virtual communities of museum Web sites in this way is beneficial to all involved in terms of increased visibility on Google.
It is a good ideal not to change the internal structure of your Web site unnecessarily, at least at the topmost levels. All search engines can only scan your Web site periodically ,and any changes are likely not to be reflected for a while, resulting in bad links from search engines until they have rescanned your W site. Ensure that the most useful subsections of your Web site have a simple Web address linked directly from the main page if possible. The BBC is particularly good at this since they need to broadcast internal Web addresses visually and verbally (e.g., see http://www.bbc.co.uk/arts also mapped from http://www.bbc.co.uk/art, http://www.bbc.co.uk/society also mapped from http://www.bbc.co.uk/culture, etc.).
In the case of major changes to a Web site, the home page should be resubmitted to the major search engines. It is only worth considering resubmission to the major search engines. As an example, in statistics collected on the Virtual Library museums pages since 1999 (http://extremetracking.com/open?login=vlmp), there are only five search engines providing more that 1% of the referrals each: Google (64.4%, http://www.google.com), MSN Search (15.5%, http://search.msn.com), Yahoo (12.4%, http://search.yahoo.com), AltaVista (2.8%, http://www.altavista.com) and Excite (2.3%, http://www.excite.com). Submitting a site to the first three of these is probably the most critical, and in particular Google (http://www.google.com/addurl.html), which has a very simple submission form with no registration required. Microsoft runs a commercial submission service, Submit It! (http://www.submit-it.com), aimed more at businesses than not-for-profit organizations. Yahoo allows submissions (http://submit.search.yahoo.com), including free submissions (http://submit.search.yahoo.com/free/request), although registration as a Yahoo user is required. After this, the law of diminishing returns very much applies. For a comprehensive list of search engines listed by country, see Search Engine Colossus (http://www.searchenginecolossus.com). In general it is not worth paying a commercial search engine submission Web site for a museum since apart from the major search engines, most others will have very little effect on traffic to a Web site.
It is best should ensure that all your Web pages are interlinked by at least one hyperlink to allow Web spiders to find them. This is especially critical if you have a database and wish this to be indexed by Google and other search engines. There should be links to the next (and previous) record in the database, for example, and the links should also be organized hierarchically since most search engines will only scan a Web site to a limited depth, which will vary depending on the search engine.
It is possible to include quite complicated and detailed metadata in Web pages if desired. (See later for a more general discussion.) For example, the Dublin Core Metadata Initiative (DCMI, http://dublincore.org) specifies many metadata terms that can be included in HTML Web pages as metatags if desired (http://dublincore.org/documents/dcmi-terms). Here is some example Dublin Core metadata that could be included in the <head> section of a Web page (adapted from http://icom.museum/vlmp):
<meta name="DC.Title" content="WWW Virtual Library museums pages (VLmp)">
<meta name="DC.Creator.name" content="Jonathan Bowen">
<meta name="DC.Creator.address" content="London South Bank University, UK">
<meta name="DC.Creator.e-mail" content="jonathan.bowen@lsbu.ac.uk">
<meta name="DC.Publisher" content="International Council of Museums (ICOM)">
<meta name="DC.Type" content="Bibliography">
<meta name="DC.Format" scheme="IMT" content="text/html">
<meta name="DC.Identifier" content="http://icom.museum/vlmp/">
<meta name="DC.Language" scheme="ISO639-1" content="en">
<meta name="DC.Rights" scheme="URL" content="http://vlib.org/admin/Copyright.html">
However, this information is not used by many search engines. At a simple level, nearly all Web pages include a title, and some include a description and keyword metadata. E.g.:
<title>Virtual Library museums pages (VLmp)</title>
<meta name="description" content="Directory of museums, part of the Virtual Library, an expert-run catalog of sections of the Web. VLmp is also supported by the International Council of Museums (ICOM) and the Museophile initiative.">
<meta name="keywords" content="museums, museum, museos, museo, musées, musée, musees, musee, museus, museu, museums, museum, galleries, gallery, libraries, library, reference, Web, directory, catalog, catalogue">
This is more likely to be taken into account by search engines. The title is displayed by all major search engines and a suitable short description line with important keywords should be included on every Web page on a Web site. The "description" metadata is often used as a brief explanation when a search engine displays a Web site. Otherwise the first few lines of the actual Web page are typically used, and these should always be as descriptive and meaningful as possible because of this. The "keyword" metadata can be used to list important keywords and phrases, perhaps in different languages if very significant. The words in all these metadata entries may be weighted to be more important for keyword matching than the rest of a Web page, depending on the search engine.
For general advice on consideration of search engines for a museum Web site, the information in Bowen & Bowen (2000) is still applicable. It is possible to assess a Web site's popularity in terms of links to it for search engines such as Google, AltaVista and HotBot (http://www.linkpopularity.com). The on-line tools available on the PageRank Web site may also be found to be useful for checking and improving a Web site with respect to search engines (http://www.pagerank.net). For more detailed information on technical aspects of Google, see Calishain & Dornfest (2004).
In this section, we have considered some of the possibilities that a museum Web master has to improve the ranking of the museum's Web site. However there are a lot of other opportunities to advance the service that the search engines and other search-based Web sites are offering to visitors, such as the personalization of search tools to make them capable of profiling the user's preferences and to act on them effectively. In the next section we consider the future and some of the customization tools that are already available in advanced Web sites offering database retrieval facilities.
Metadata Issues
After analyzing Web topology in detail and its effects on the activities of search engine crawlers, we contest that it is best not to rely on the addition of metadata to all information available on museum Web sites, as well as in all other Web pages, in order to retrieve information on the Web, although this may be possible on a smaller and perhaps collaborative scale (Wisser, 2004). Let us start our discussion by considering the Semantic Web (SW, http://www.semanticWeb.org), which can be seen as the grand challenge project of adding metadata automatically or manually to the entire Web:
The main idea behind SW is that we try to extend the current Web with additional information to make it possible that computers do understand the content of Web pages. Of course, we are not going to remove or replace the current Web. The SW is an extension, an additional layer on top of the already existing Web (Van Harmelen 2003: 2).
The basic idea of the Semantic Web is to add a layer to the Web, as it is now, to provide the users with extra information about the content and the meaning of Web documents so that users can more easily access what they are searching for. Though this project seems to be very promising for restricted parts of the Web, such as good categories for e-commerce, library catalogues or specific museum collections, it seems to be at least problematic, from an epistemological point of view, to create a standard vocabulary for metadata that is suitable for application to every area of knowledge. The creation of ontologies is a very intractable task, and nobody knows if the effort will ever end with a consistent worthwhile result.
Moreover, it is not clear at the moment if machines should be able to attribute semantic tags directly to data, or if we need a group of people with a librarian's mentality to add metadata information to all the resources in a normal way. Both solutions, though involving different difficulties, seem to share the characteristics of being a huge amount of work that would take a long time and risk the need for a never-ending checking endeavor. If we look at the Semantic Web, according to Tim Berners-Lee vision, it will "add logic to the Web" (Berners-Lee, 1998). So even if we suppose that it is possible to overcome all the various practical obstacles and achieve the desired result, what we will end up with is something that is not similar to the Web as Berners-Lee invented and we have learnt to appreciate, but instead a completely new system. It will become a semantic-oriented database, and it will lose the associative and innovative links opportunities anticipated by Bush (1945), being restricted to the logical structure imposed by the metadata layer that is not capable of taking into account the serendipitous connections between different topics.
The discussion about metadata applied to the museum collections' cataloguing process necessarily starts with acknowledgement that it is a useful tool to organize materials and objects in order for them to be sorted out when needed; however there are some issues that should be considered very carefully before starting such an undertaking.
In order to add metadata to collections of data, it is necessary to make a huge cataloguing effort; even if the archival strategy inside one institution is very consistent, there is no way to guarantee the complete objectivity of the endeavour. Whoever has even a little experience with attaching metadata to collections knows that this procedure is inevitably influenced by the attitude of the interpretation made by the archivist and is similar to a translation of catalogued documents. Metadata are pictures, images of the objects themselves that offer a unified vision of the database of the collection, but there is a cost for the creation of the homogeneous vision: the removal of all the characteristics that cannot be described by the fields defined at the beginning.
As an example of the subjectivity and sometimes inadequacy of some metadata standards, consider the Dublin Core Metadata Initiative (DCMI, http://dublincore.org), hosted by the Online Computer Library Center (OCLC, http://www.oclc.org), that provides a significant joint effort by those interested in the production and distribution of on-line content. This initiative is to produce a metadata standard in order to catalogue on-line resources. Looking at the "elements" of the description, it can be seen that they were conceived with consideration of offline resources such as books and articles in journals. Elements such as Date, Publisher, Type, Source (a reference to a resource from which the cataloguing object is derived), Coverage (spatial localization, temporal localization, jurisdiction) are inadequate for the description of on-line resources, and possibly even misleading for a correct interpretation of their dynamic, multimedia, multi-author nature.
Moreover, we have the issues related to comparisons between different cataloguing styles in different institutions, despite the fact that they may be dealing with the same types of documents or objects. Standards can be misleading, but if they are not used it is even more difficult to compare different databases or pose queries on them to obtain relevant information that is available. When content is obtainable on-line, the retrieval techniques should take into account not only the internal cataloguing rules, but also how these rules can be linked to rules adopted by other similar archives on the Web. It is idealistic to imagine that a unique cataloguing style for all documents available in museums around the world can be achieved. Such a project would not only be almost impossible to realize, but would also be contrary to the spirit of the Web that has more to do with the associative character of information that is freely obtainable.
In conclusion, there is an open question that needs to be raised: is the effort of attaching metadata to museum collections proportionate to the benefits offered in terms of facilitating access of material in an on-line environment, such as the Web? It is clear that the use of metadata is helpful internally in order to preserve, archive and organize resources, but it is less clear if it is the right direction to pursue for on-line access of materials. In the last section of this paper, we will consider the future of search engine technology. These approaches have not necessarily been applied directly to museums collections, but it is possible that they could be used beneficially in such an environment.
The Future
It is impossible to predict the development of searching on-line with any accuracy in our view. However, this section will consider some eclectic issues that we believe to be important and that have the potential to be developed significantly with regard to search engine technology and usage.
There are appealing user interface developments in the presentation and visualization of search engine results as well as other aspects. See, for example, KartOO (http://www.kartoo.com), a meta-search engine with a visual display map that helps to emphasize the relative importance of different related keywords through their displayed size, together with links between them (Bowen et al., 2003).
There is also interesting research on content-based information retrieval (CBIR) for both 2D and even 3D images, research which could be increasingly useful for searching museum collections that have been digitized. See, for example, the European SCULPTEUR Project (Semantic and content-based multimedia exploitation for European benefit, http://www.sculpteurWeb.org), including 3D object searching for museums (Goodall et al., 2004). However, image search is beyond the main scope of the current paper, which concentrates on text-based searching with search engines in finding existing (museum-related) information on-line.
The Virtual Library museums pages (VLmp) were an early attempt to form a linked collection of museum Web sites allowing individuals in different countries to participate in a virtual community and in an altruistic spirit (Bowen, 2002). This could be developed further into a collaboratively linked set of museum collections' databases where objects across a wide range of museums could be searched as easily as the Web is searched today. However, this remains a vision for the future (Bowen, 2000), despite some limited successes like Australian Museums & Galleries Online (AMOL, http://amol.org.au), conceived in the early 1990s to provide combined access to a number of Australian museum collections and soon to be relaunched as the Collections Australia Network (CAN). Such efforts are to be commended, but we really need museum collection searching at the meta-level, combining this and other similar efforts around the world, to provide a successful and widely available resource of international value.
The distributed Web mining research area is multifaceted, so we can identify various streams that belong to it in one sense or another, but they all share the view that a unique, centralized data repository management is not the best way of investigating the variety of content on the Web. They also mainly rely on the idea that machine-learning bottom-down strategies can help both the indexing process and the personalization of results according to users' preferences. We can distinguish at least three different approaches:
- Deep Agents and focused crawling strategies that allow the crawlers to create their own index while browsing the pages, without relying on a unique repository. This paper is not the right place to go more deeply in details in the present research in the field; for more information on this topic, see Gori Numerico (2003) and for further information see, for example, Diligenti et al. (2000) and Chakrabarti et al. (1999).
- Shallow Agents, personalization issues and "push" technology.
- Peer-to-Peer (P2P) clustering creation.
We consider the last two aspects above in more detail in the following sections.
Personalization Issues
Despite the existence of many search engines, searching on the Web is still not an easy task (Shanfeng et al., 2001). Investigation into the use of Web search engines indicates that users can typically encounter a number of difficulties. These include the issue of finding information relevant to their needs and also the problem of information overload (Stobart & Kerridge, 1996), as illustrated in the earlier case studies. Typically, a search on Google, MSN Search, Yahoo! or AltaVista, for example, can result in thousands of hits, many of which will not be pertinent to a users enquiry. This is due in part to the keyword search approach, which does not necessarily capture the user's intent. Another reason for irrelevant results from search engines is a semantic gap between the meanings of terms used by the user and their use in Web pages stored by search engines. In addition, each search engine normally has its own non-customizable ranking system, where users cannot tell the search engine what preferences to use for search criteria (Kerschberg et al., 2002).
Software called intelligent searching agents has been developed in order to try to ameliorate these problems. Typically, these tools include "spider" or "Web crawler" software (http://en.wikipedia.org/wiki/Web_crawler) that can be trained by the user to search the Web for specific types of information resources. The agent can be personalized by its owner so that it can build up a picture of individual likes, dislikes and information needs. Once trained, an agent can then be set free to roam the network to search for useful information sources. Different methods of gathering the user's data are applied by means of various personalization techniques and associated agents.
Relevance feedback, for example, is a powerful technique having its roots in traditional textual Information Retrieval (IR) research (Li et al., 2001). It is an interactive process of improving the retrieval results by automatically adjusting the original query based on information feedback by users about the relevance of previously retrieved documents. In the metasearch engine SavvySearch (Shanfeng et al., 2002), for example, now Search.com (http://www.search.com), relevance feedback is used for selecting suitable source search engines. Two types of events, namely no results found and actual visits made are identified as negative or positive feedback from the user (http://www.search.com/help/index.html?tag=se.fd.box.main.help).
Another commonly used technique is user profiling, which, unlike relevance feedback, has its origins in the field of information filtering and recommendation. In user profiling, the system monitors a stream of information and selects what matches the user's interests (Li et al., 2001). These interests can be inferred explicitly by asking the user to fill in a profile. Yahoo, for example, has taken advantage of its relationship with visitors to deliver more tailored answers in specific areas: its yellow pages, weather information and My Yahoo! (http://my.yahoo.com) sections all use members' ZIP codes or other personal data to deliver tailored information (Olsen, 2003).
A similar concept is applied in Google personalized (http://labs.google.com/personalized), which invites users to create a profile by selecting categories of interest from a pre-selected list. Once the profile has been defined, users can choose the degree of personalization they want via a slide bar at the top of the screen. At the lowest setting the results appear the same as users would get with the standard Google search engine. For instance, users expressing an interest in art and searching for the word "Morandi" (http://www.google.com/search?q=Morandi) will receive listings on the artist as opposed to receiving links to the Italian singer. The degree of personalization can also be adjusted on a sliding scale in real-time, allowing users to receive results that follow their preferences or are more general in nature (Pruitt, 2004). The type of personalization that Google's prototype offers is fairly minor; it allows users to check a few areas of interest but no more than this. For example, demographic preferences cannot be selected, and there are not even very many subcategories from which to choose. However the value of the application, as underlined by Goodman (2004), is in the functionality of the slider or dial, which allows the user to watch the impact of changing settings on how the search results are ranked.
Explicit user profiling depends on the willingness of users to provide information about themselves and their awareness of self-needs. However, many Web users prefer not to provide personal information if they do not benefit from it immediately. A search engine user may prefer not to spend time creating a profile when searching for information for a research paper. In this case, the system has to construct the user model by inferring knowledge from the user's behavior and exploiting user feedback about the relevance of documents implicitly.
Many search engines already use some rudimentary implicit personalization features. AltaVista (http://www.altavista.com), for example, uses so-called "geotracking" technology to detect visitors' Internet Protocol (IP) addresses and guess their geographical location. That can provide useful context for some searches, for example, in returning museum-related results for a query on "Picasso" from a user based in France (Olsen, 2003). In a more sophisticated way, WebWatcher (http://www.Webwatcher.org) also monitors and learns from the actions taken by its users. It continuously adapts its behavior and improves its efficiency when visiting Web sites that it has accessed in the past. WebWatcher's learning is based on an active user profile, the interests that the user has expressed during the current search and the Web page that is being currently accessed (Vozalis et al., 2001). Another example is Eurekster (http://www.eurekster.com), a search engine able to learn from the user's search habits; if the user follows a link and spends more than a minute on the page, that link will be closer to the top the next time the user searches that term (see later for further details).
Once the data concerning the user's interests has been collected either implicitly or explicitly or even in both ways, which is often the case e.g., see the software agent, Syskill & Webert, (Pazzani et al., 1996) appropriate search results are determined and delivered. This process usually follows one or a combination of the following techniques: content based or collaborative filtering. The content-based approach first represents the users preferences and then evaluates Web pages relevance in terms of its content and user preferences. WebWatcher falls into this category. On the contrary, the collaborative approach determines information relevancy based on similarity among users rather than similarity of the information itself (Kerschberg et al., 2002).
An example of such system is Eurekster (http://www.eurekster.com), which allows the user to get his/her friends to join one of the service's "Searchgroups". The links the friends like will appear higher in the users results when he/she searches on the same term. For example, take a search for "Sisley," the popular Impressionist artist. Without refinement, Eurekster brings back a variety of results, leading off with the clothing company. But the user is thinking of the impressionist artist who is listed only in position three. By clicking on the site, the user interest in it is registered by Eurekster (implicit user profiling). Now, if one of the registered friends of the user does the same "Sisley" search, the artist's Web site moves up to position one, with a little Eurekster "e" icon next to it. That's to alert them that someone in their network likes this site. Eurekster does more than refine the results. It can also show the user the things that other people in his/her network are looking for. So when the user searched for "Sisley," anyone else in his/her network sees that query get listed in the "Your Friends Recent Searches" area in the right-hand column of the Eurekster search results page. To protect privacy, Eurekster makes it possible to do a "private search" by checking a box below the search box (Sullivan, 2004).
As the Web can be considered a social network, this property can be exploited for search purposes also on the side of potential explicit or implicit social collaboration in the organization and categorization of the network information. If we can create devices that allow us to share and organize collectively the knowledge of each individual member of the community, and if we succeed in creating methods to propagate trust and control distrust (Guha et al., 2004), then we can benefit from the expert evaluation of links and from the creation of a collectively built, trustworthy, free knowledge base (Resnick et al., 1994).
In the social data mining systems, which represent an enhanced version of the collaborative categorization, it is not even required that the users be engaged in an explicit contribution to the community. The system seeks to exploit users behaviours to detect the information implicit in the records of their existing activities (Amento et al., 2003).
A successful example of implementation using these techniques is the Amazon knowledge management system, which monitors the buying habits of previous clients to provide prospects with suggestions which are frequently very effective, relying on preferences of other similar customers. The overall system also benefits from the creation of the sense of belonging to a virtual community of shared interests (Beler et al., 2004).
The hypertextual, distributed and associative nature of the Web implies the necessity of innovative research strategies in order to overcome the weaknesses and shortcomings of the current information retrieval techniques. Distributed and social systems of data mining offer promising approaches to Web search techniques and methods. Collectively, museum Web sites are in a very privileged position to exploit community building in order to retrieve, suggest, and evaluate their available content. Though the cultural institutions are not particularly powerful from the economic point of view, they are very rich in term of the quality of the audience. They attract a range of people from specialized professionals to a well-cultivated community that, if correctly stimulated, could be eager to communicate with each other and build up the collaborative filtering structure to spread and share information.
Push Versus Pull Technology
Until now we have considered ways to allow users "to pull" the information desired from the Web through search engines. However, there is also another way to get to the same information; that is to say, through the so called "push technology" . The concept of information "push" technology originated as a way to automate the searching and retrieval of information from the Internet, such as stock market, news and weather forecasts. Based on user-defined criteria, a push application automatically searches a database for specific information and delivers it straight to the end-user's desktop. It is a convenient way to receive information the user may not otherwise know exists, and eliminates the need to go and find it (Murray, 2002).
In simplest terms, push refers to software that delivers Web information to consumers, rather than forcing consumers to forage through the Web to find it. The concept attracted considerable attention in the mid-1990s when PointCast, a now-defunct company founded in 1992, launched the first push technology-based product to deliver customized news and other information to users' desktops. PointCast Network was free. To use it, the user needed to download the PointCast client program, which was available from PointCast's Web site and many other places. The initial success of this product, as well as similar ones like BackWeb and Castanet, was mainly due to the fact that it seemed to reduce the problem of information overload. But despite the clamor, push technology has encountered some difficulties in gaining users' confidence. Some early detractors, in fact, complained that having their computer automatically log onto the Web and retrieve data on a predetermined schedule was obtrusive; others objected that the filters employed by these programs were not smart enough to sift the truly relevant information from the unnecessary. And many others simply saw a basic contradiction between the concept of push and the interactivity of the Web: push technology renders the user passive, as with television (Flynn, 1998).
Yet many analysts say that at least in theory, the idea of aggregating Web content and then delivering it to users makes sense (Flynn, 1998), as proven by the fact that different push technology-based products keep on being launched onto the market. The last of a long list of companies which have taken up push technology to facilitate the search of information by their users is Google Alert (http://www.googlealert.com, not affiliated with Google). This alert facility tracks anything on the Web by automatically running daily personalized Google searches and alerts users to new results by email, RSS or an on-line browser. The driving vision beyond this project, as admitted by Gideon Greenspan, Google Alerts founder, was "to cut through information overload by providing a personalized service that connects people directly with their interests" (GoogleAlert, 2004).
These same principles could be also applied in a virtual museum context, where some institutions especially the big ones, whose Web contents get updated on a daily basis, could set up personalized alert systems that identify recent additions to the Web site and alert the user, based on specified preferences or related preferences of similar users. This is for example the case of the Louvre or the National Museum of Photography, Film and Television (http://www.nmpft.org.uk) in Bradford, UK, which are planning to introduce systems based on this philosophy: instead of providing everybody with standard information concerning the museum's activities, services and products, the personalized alert system will allow the virtual visitor to set their own profile by defining their personal interests on a fill-in form and sending an e-mail address or a mobile phone number. Whenever a relevant exhibition, conference or concert of interest is about to take place, the user will be automatically informed about it by e-mail or SMS text message (Filippini-Fantoni, 2003). By doing so, the user will find out more easily about information of interest without making the effort to visit the museum's Web site and look for it. By facilitating access to information with a minimal effort from the user, such alert systems can improve the relationship between the user and the institution. This is why we can foresee that these push solutions will find easy application in the museum context.
Peer-to-Peer Searching
Besides personalization and push technology, there is another interesting stream of research that we believe will offer interesting perspectives for cultural institutions and heritage information archive. Distributed Information Retrieval (DIR) studies problems of searching distributed and heterogeneous repositories. The distributed searching standard, Z39.50 (ISO, 1998; http://www.loc.gov/z3950/agency) exists but is rather complicated and not very widely used in practice. In order to obtain results using DIR, there are various issues that need to be tackled: the identification of a common language for the resource description, the creation of repository selection schemes and the development of methods for merging different ranked lists returned from searches in inhomogeneous archives. Peer-to-Peer (P2P) networks are distributed and dynamic; they allow the participation of many members and the use of low cost systems, built on the principle of utilizing unused computing resources.
SETS (Search Enhanced by Topic Segmentation) is a very promising project in this area. It puts together the machine-learning tradition of topic segmentation studies and social network results, integrating them with P2P search methods (Bawa et al., 2003). This is a topic segmentation based network that provides efficient search facilities on P2P networks. The key idea is to arrange sites in a network such that a search query probes only a small subset of sites where most of the matching documents reside. In the network, there are two kinds of links: short distance links connect sites within the same content segment; long distance links connect pairs of sites from different segments, so that queries are routed only in the relevant areas of the network, without invading all the networks with irrelevant traffic. The idea behind this project is to create various dynamic networks based on subject clustering that can be used to route questions matching the subject of the specific sub-network.
Museums could create a special Peer-to-Peer (P2P) dynamic network that connects different institutions according to their areas of interests. The repository of documents should not be kept centrally, but as in P2P networks be distributed all over the network. This lack of centralized network has different advantages: it reduces the cost of using a unique repository (and the consequent need of making it profitable as in search engines ones), it guarantees better coverage of relevant materials due to the dynamic control within each subnetwork, and it favors the precision of results in terms of the quality of the queries that match, due to the machine-learning dynamic clustering of similar Web sites. Note that the system works on Web sites, not on individual Web pages like search engines.
Conclusion
Information retrieval techniques are one of the key issues for the development of the Web as the huge repository of worldwide information. It is still an open question which is the direction of research to pursue in order to achieve the best results. We are sure that there is still space for new paradigms and new models since we are just at the beginning of the research in the field. However it is critical that cultural institutions such as museums, the heritage and memory keepers, be aware of the issues under discussion and not rely completely on commercial enterprises for solutions. They must provide interesting suggestions to commercial partners and underline for them the necessity for qualitative evaluation of results. For example, an open source search engine is a possible route to the future (e.g., see http://www.nutch.org). It is desirable for the museum community to participate in or monitor joint initiatives like SCULPTEUR (Goodall et al., 2004) and the DELOS European Network of Excellence on Digital Libraries (http://www.delos.info) that started in 2004, for example to investigate and check for new promising solutions to content-based information retrieval problems with respect to museum collections on the Web.
Acknowledgements
The Leverhulme Trust (http://www.leverhulme.org.uk) funded the research by Teresa Numerico in this paper. Museophile Limited (http://www.museophile.com) provided financial support for Jonathan Bowen.
References
Arasu, A., J.Chi, H.Garcia-Molina, A.Paepcke & P.Roghavan(2001). Searching the Web. ACM Transactions on Internet Technology 1(1), 243, August. http://portal.acm.org/citation.cfm?id=383035
Barabási, A.L. (2002). Linked, Cambridge, MA: Perseus Publishing. http://portal.acm.org/citation.cfm?id=829575
Bawa, M., G.Manku, & P.Raghavan (2003). SETS: Search Enhanced by Topic Segmentation. In Proc. 26th International ACM Conference on Research and Development in Information Retrieval (SIGIR). http://citeseer.ist.psu.edu/bawa03sets.html
Beler, A., A.Borda, J.P.Bowen & S. Filippini-Fantoni (2004). The building of online communities: An approach for learning organizations, with a particular focus on the museum sector. In J. Hemsley, V. Cappellini & G. Stanke (Eds.), EVA 2004 London Conference Proceedings, London, UK, July 2630. London: EVA Conferences International, 2.115. http://arxiv.org/abs/cs.CY/0409055
Berners-Lee, T. (1998). Semantic Web road map. http://www.w3.org/DesignIssues/Semantic.html
Borges, J. L. (1941) La Biblioteca de Babel. In Ficciones. Madrid: Alianza, 1971. http://rehue.csociales.uchile.cl/rehuehome/facultad/publicaciones/autores/borges/borges_n1.htm. English translation, The Library of Babel. In J. L. Borges, Labyrinths, Harmondsworth: Penguin, 1970. http://jubal.westnet.com/hyperdiscordia/library_of_babel.hml
Bowen, J. P. (2000). Its just a tool though: No its not, its an alien life form. Spectra 27(1), 1920. Museum Computer Network, USA. http://www.artsconnected.org/millennialmuseum/displayitem.cfm?item=9
Bowen, J. P. (2002). Weaving the museum Web: The Virtual Library museums pages. Program: Electronic Library and Information Systems 36(4), 236252. http://dx.doi.org/10.1108/00330330210447208
Bowen, J. P. & J.S.M.Bowen (2000). The Web site of the UK Museum of the Year, 1999. In D. Bearman & J. Trant (Eds.), Museums and the Web 2000 Proceedings, Minneapolis, USA, 1619 April. Archives and Museum Informatics. http://www.archimuse.com/mw2000/papers/bowen/bowen.html
Bowen, J. P. & S. Filippini-Fantoni (2004). Personalization and the Web from a museum perspective. In D. Bearman & J. Trant (Eds.), Museums and the Web 2004: Selected Papers from an International Conference, Arlington, Virginia, USA, 31 March 3 April. Toronto: Archives and Museum Informatics, 6378. http://www.archimuse.com/mw2004/papers/bowen/bowen.html
Bowen, J. P., M.K.Houghton & R.Bernier (2003). Online museum discussion forums; What do we have? What do we need? In D. Bearman & J. Trant (Eds.), Museums and the Web 2003 Proceedings, Charlotte, USA, March 1922. Archives and Museum Informatics. http://www.archimuse.com/mw2003/papers/bowen/bowen.html
Brin, S. & L.Page (1998). The anatomy of a large-scale hypertextual Web search engine, Computer Networks and ISDN Systems 30, 107117. http://citeseer.ist.psu.edu/brin98anatomy.html
Bush, V. (1945). As we may think, The Atlantic Monthly 176, 101108, July. Reprinted in P. A. Mayer (Ed.) (1999), Computer Media and Communication, Oxford University Press, Oxford, 23-36. http://www.ps.uni-sb.de/~duchier/pub/vbush/vbush-all.shtml
Calishain, T. & R.Dornfest (2004). Google hacks: Tips & tools for smarter searching, 2nd edition. OReilly, 2004. http://www.oreilly.com/catalog/googlehks2
Chakrabarti,S., M.van den Berg & B.Dom (1999). Focused crawling: A new approach to topic-specific Web resource discovery. Proc. 8th International World Wide Web Conference, Toronto, Canada. Elsevier Science. http://www8.org/w8-papers/5a-search-query/crawling
Cho,J. & S.Roy (2004). Impact of search engines on page popularity. Proc. 13th International Conference on World Wide Web, New York, USA. ACM Press, 2029. http://doi.acm.org/10.1145/988672.988676
Cusmano, M. A.(2005). Google: What it is and what it is not. Communications of the ACM 48(2), 1517, February. http://portal.acm.org/citation.cfm?id=1042107
Derrida,J. (1996). Archive fever. Chicago & London: The University of Chicago Press. http://www.press.uchicago.edu/cgi-bin/hfs.cgi/00/13189.ctl
Diligenti, M., F.Coetzee, S.Lawrence, C.Giles & M.Gori (2000). Focused crawling using context graphs. Proc. 26th International Conference on Very Large Databases (VLDB 2000), El Cairo. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA. http://portal.acm.org/citation.cfm?id=645926.671854 & http://citeseer.ist.psu.edu/diligenti00focused.html
Diligenti,M., M.Gori & M.Maggini (2002). Web page scoring systems for horizontal and vertical search. Proc. 11th International World Wide Web Conference, Honolulu, USA. ACM Press, 508516. http://www2002.org/CDROM/refereed/629 & http://doi.acm.org/10.1145/511446.511512
Dorogovtsev, S.N., J.F.F.Mendes & A.N.Samukhin (2001). Giant strongly connected component of directed networks. Physics Review E 64, 025101. http://arXiv.org/abs/cond-mat/0103629 & http://xxx.lanl.gov/abs/cond-mat/0103629
Faloutsos, M., P.Faloutsos & C.Faloutsos (1999). On power-law relationships of the Internet topology. Proc. ACM Special Interest Group on Data Communications (SIGCOMM), August. ACM Press, 251262. http://citeseer.ist.psu.edu/michalis99powerlaw.html
Filippini-Fantoni, S. (2003). Museums with a personal touch. In J. Hemsley, V. Cappellini & G. Stanke (Eds.), EVA 2003 London Conference Proceedings, University College London, UK, July 2226. London: EVA Conferences International, s25:110. http://www.ecdc.nl/publications/papers/Museums%20with%20a%20personal%20touch.pdf
Flynn, L. J.(1998). Why 'push' got shoved out of the market. CyberTimes, February 16th. http://www.nytimes.com/library/cyber/week/021698push.html
Goodall, S., P.H.Lewis, K.Martinez, P.A.S.Sinclair, F.Giorgini, M.Addis, M.Boniface, C.Lahanier & J.Stevenson (2004). SCULPTEUR: Multimedia retrieval for museums. In P. Enser, Y. Kompatsiaris, N. E. OConnor, et al. (Eds.), Image and Video Retrieval: Third International Conference, CIVR 2004, Dublin, Ireland, July 2123. Berlin: Springer-Verlag, Lecture Notes in Computer Science 3115, 638646. http://springerlink.metapress.com/openurl.asp?genre=article&issn=0302-9743&volume=3115&spage=638
Goodman, A.(2004). Make your own pie: Googles personalization, merely a taste of things to come. Traffic,
GoogleAlert (2004). Google alert releases revolutionary personalized search technology, Google Alert, Indigo Stream Technologies. http://www.googlealert.com/news-4-27-2004.php
Gori, M. & T.Numerico (2003). Social network and Web minorities, Cognitive Systems Research 4(4), 355364, December. Elsevier. http://dx.doi.org/10.1016/S1389-0417(03)00016-0
Guha, R., R.Kumar, P.Raghavan & A.Tomkins (2004). Propagation of trust and distrust. Proc. 13th International Conference on World Wide Web, New York, USA. ACM Press, 403412. http://dx.doi.org/10.1145/988672.988727 & http://tap.stanford.edu/trust04.pdf
, 334. http://dx.doi.org/10.1007/b83557 & http://www.mpi-sb.mpg.de/units/ag5/teaching/ss02/Literatur/Websifterii.pdf
Henzinger, M. & S.Lawrence (2004). Extracting knowledge from the World Wide Web. Proceedings of the National Academy of Science, April, 51865191. http://www.pnas.org/cgi/reprint/101/suppl_1/5186
ISO (1998). Information and documentation Information retrieval (Z39.50) Application service definition and protocol specification. ISO standard 23950, International Organization for Standardization. http://www.iso.org/iso/en/CatalogueDetailPage.CatalogueDetail?CSNUMBER=27446
Kumar, R., P.Raghavan, S.Rajagopalan & A.Tomkins (2002). The Web and social networks. IEEE Computer 35(11), 3236, November. http://doi.ieeecomputersociety.org/10.1109/MC.2002.1046971
Lawrence S. & C.L.Giles (1998). Searching for the World Wide Web, Science 280, 98100, April 3. http://www.sciencemag.org/cgi/content/abstract/280/5360/98
Levene, M. & R.Wheeldon (2003). Navigating the World-Wide-Web. In M. Levene & A.Poulovassilis (Eds.), Web dynamics: Adapting to change in content, size, topology and use. Berlin: Springer-Verlag, 117151. http://citeseer.ist.psu.edu/levene03navigating.html
Li, Q., J.Yang & Y.Zhuang (2001). Web-based multimedia retrieval: Balancing out between common knowledge and personalized view. Proc. 2nd International Conference on Web Information Systems Engineering (WISE01), December 36, Volume 1. IEEE Computer Society, 92101. http://ieeexplore.ieee.org/xpl/abs_free.jsp?arNumber=996470 & http://www.cs.cityu.edu.hk/~csqli/research-projects/Octopus/papers/wise01jyang.pdf
Murray, P.(2002). Feeling the pull of "push" technology. Computer Weekly, October 24. http://www.computerweekly.com/Article116824.htm
Olsen, S. (2003). Searching for the personal touch. CNET News.com, August 11. http://news.com.com/2100-1024_3-5061873.html
OReilly, D. (2004). Search Engines Get personal. Leading sites explore how to draw on user interests and common queries to serve up custom findings, PCworld, August 4. http://pcworld.about.com/news/Aug042004id117257.htm
Pazzani, M., J.Muramatsu & D.Billsus (1996). Syskill & Webert: Identifying interesting Web sites. Proc. 13th National Conference on Artificial Intelligence (AAAI-96), Portland, USA, August 48. American Association for Artificial Intelligence. http://www.ics.uci.edu/~pazzani/Publications/aaai-Webert.pdf
Puitt, S. (2004). Google gets personal. New service delivers customized search results based on user preferences in PCworld, March 29. http://www.pcworld.com/news/article/0,aid,115425,00.asp
Resnick, P., N.Iacovou, M.Suchak, P.Bergstrom & J.Riedl (1994). GroupLens: An open architecture for collaborative filtering of networks. Proc. ACM Conference on Computer Supported Cooperative Work (CSCW94), Chapel Hill, NC, USA, November. ACM Press, 175186. http://dx.doi.org/10.1145/192844.192905
Shanfeng, Z., D.Xiaotie, C.Kang & Z.Weimin (2002). Using online relevance feedback to build effective personalized metasearch engine. Proc. 2nd International Conference on Web Information Systems Engineering (WISE01), Volume 1, December 36, Kyoto, Japan. IEEE Computer Society, 262268. http://csdl.computer.org/comp/proceedings/wise/2001/1393/01/13931262abs.htm
Sherman C. & G.Price (2001). The invisible Web: Uncovering information sources search engines cant see. CyberAge Books. http://www.invisible-Web.net
Stobart, S. & S.Kerridge (1996). WWW search engine study, November. http://www.ariadne.ac.uk/issue6/survey
Sullivan, D. (2004). Eurekester launches personalized social search. Search Engine Watch, January 21. http://searchenginewatch.com/searchday/article.php/3301481
Valdes-Perez, R. (2004). Narrowing the search. CNET News, November 22. http://news.com.com/2010-1038_3-5460452.html
Van Harmelen, F. (2003). The future of search engine search and you will find. An interview with Franck Van Harmelen. Network 2, 16. http://lgxserve.ciseca.uniba.it/lei/ai/networks/03-2/vanharmelen-en.pdf
Vozalis, E., A.Nicolaou & K.G. Margaritis (2001). Intelligent techniques for Web applications: Review and educational application. Proc. 5th Hellenic-European Conference on Computer Mathematics and its Applications (HERCMA), Athens, Greece. http://macedonia.uom.gr/~mans/papiria/hercma2001.doc
Wisser, K. (2004). Museum metadata in a collaborative environment: North Carolina ECHO and the North Carolina Museums Council Metadata Working Group. In D. Bearman & J. Trant (Eds.), Museums and the Web 2004 Proceedings, Arlington, Virginia, USA, 31 March 3 April. Archives and Museum Informatics. http://www.archimuse.com/mw2004/papers/wisser/wisser.html
Cite as:
Numerico, T., J. Bowen and S. Filippini-Fantoni, Search Engines and Online Museum Access on the Web, in J. Trant and D. Bearman (eds.). Museums and the Web 2005: Proceedings, Toronto: Archives & Museum Informatics, published March 31, 2005 at http://www.archimuse.com/mw2005/papers/numerico/numerico.html
April 2005
analytic scripts updated:
October 2010
Telephone: +1 416 691 2516 | Fax: +1 416 352 6025 | E-mail: