Bryan Solomon, Victoria & Albert Museum, United Kingdom
Abstract
In Museums with diverse collection types, the objective of creating an accessible repository which spans the entire collection is fraught with difficulty, in terms of systems and organizational culture. For example, at the V&A, separate systems (managed by separate departments) store information about bibliographic objects, non-bibliographic objects, and archives. Yet both the public and Museum staff think of and work with the collection as a single entirety. Conservation may need to conserve both bibliographic objects and non-bibliographic objects; the Museum needs to consider loans and exhibitions that will span books, objects and the archive; and the public seeks information about the entire collection on-line.
The V&A's Core Systems Integration Project (CSIP) seeks to address this need by making an aggregation of this information available. The project has taken the view that in aggregating data, it must not change where data is mastered (i.e., all editing remains in the “core systems”). Therefore the technical architecture of this “Common Data Model” loosely based on SPECTRUM, which identifies the equivalencies (and non-equivalencies) of the aggregated information, will be made available through a “Web Services” layer, rather than by means of a data warehouse.
Because the language of “Web Services” is XML, (i.e. it receives its query, and formulates and sends its response in XML), it is ideally suited to light-weight browser-based applications that can use the information in accordance with the functionality they are designed to address. The IT industry calls this kind of technical architecture “a services oriented architecture” (SOA). But for the Web, and indeed for Museums on the Web, the potential of Web Services is much wider than providing an internal standard that helps to structure an application layer. Today Web sites are largely built around the notion of providing html that (even when sourcing a database that is accessed through search and retrieve) is static in the way it is presented and what can be done with it. Information from separate sites cannot be combined. Web services addresses this by offering a means of providing access to the base data, allowing the world to do what it likes with that data.
Keywords: Spectrum, SOA, SOAP, portal, integration, Web services
1. Introduction
On their Web site, the World Wide Web Consortium (W3C) offer a broad brushstroke description of what Web Services can offer:
Web services provide a standard means of interoperating between different software applications running on a variety of platforms and/or frameworks. Web services are characterized by their great interoperability and extensibility, as well as their machine-processable descriptions, thanks to the use of XML. They can be combined in a loosely coupled way in order to achieve complex operations. Programs providing simple services can interact with each other in order to deliver sophisticated added-value services (http://www.w3.org/2002/ws/Activity).
Typical of the hype that has surrounded Web Services during the last eight years, this statement appears to say that Web Services are the answer to all of our problems - they allow different software applications to talk to each other, they are flexible and adaptable, they make complex things simple (on that count alone, one might say, they are highly suited to the heritage sector), and they even result in something that is deemed 'sophisticated'.
The skeptics, however, have had their day, because some eight years on, Web services persist and service-oriented architectures continue to grow: one cannot go far on the Web today without encountering a Web service running in the background. This paper charts the course of a project called the CSIP (Core Systems Integration Project), which will implement a Web services layer at the V&A as a way of providing access to a repository of information on our objects. The project will enable a variety of applications to 'interoperate' by making use of that information (i.e. consuming it) and publishing the results in the contexts of their own functional requirements. The project also gives rise to flexibility because once the services are in place, we will be able to supplement the initial applications with a feasible development program based on building lightweight and browser-based applications. But at the heart of the project is the challenge of agreeing to the repository itself: a 'common data model' - on one level an aggregation of records which encompasses the entire collection, and on the other a metaphor for the necessity of bringing the Museum's departments closer together. It is through this task that the project seeks to simplify the complex. Web Services per se do not provide a solution to all of these tasks, but they have offered a framework around which we have been able to identify and manage the tasks, and make progress on the project.
The final part of the paper will speculate on how this experience might be transferable to the wider Museum community. In the same way that we have focused on SOA (Service Oriented Architecture) to offer a repository that spans the entire collection within the Museum, it is conceivable that Museums could look to SOA to provide aggregates of object records across many Museums in a way which avoids some of the pitfalls that have dogged such projects in the past. Such a vision, however, invokes a timely paradigm shift in terms of the way object/collection-related content is presented.
2. The Problem
Like many Museums or Galleries whose objects number millions or hundreds of thousands (rather than thousands or tens of thousands), the V&A has historically stored its records of objects in many different information stores, the dimensions of which were often dictated by the particulars of the groupings (or sub-groupings) of the collection. Spurred on by Information Technology, the last 15 or so years have seen a movement towards aggregating records of objects, often driven by the need to simplify and centralize support services such as conservation, gallery projects (and even IT), and the need to provide singular information portals such as the Web site. The process of digitizing the records of the objects in collections and pooling them centrally has not always been without pain, and a somewhat checkered path (the story of which is well beyond the scope of this paper) has led to the status quo where we can discern three well established central source data repositories: one for objects hereafter referred to as CIS (Collections Information System); one for bibliographic objects (essentially books) referred to as the NAL (the National Art Library, which uses a system called Dynix Horizon); and one for the Archive, or descriptions of collected materials, encoded in the EAD DTD standard (but referred to in this paper as the Archive). A classification of collections in this form is perhaps typical of large Museums and Galleries which have over the years seen processes of amalgamation and separation.
Although this triumvirate of repositories is on the one hand concerned with the Museum's objects, the way in which each has grown separately (dictated by the priorities of the departments to which they belong and their responsibilities towards the primary users of the information) has meant that each system is very different in terms on both an informational and technical level. The NAL system, for example, uses a complex system of indices to manage the records (typical of all library systems, in order to make searching for non-expert end users effective), and this means search and retrieval are on a technical level very separate tasks. CIS (the object system) makes no such distinction, but does see its contents as whole objects and as parts of an object - intuitively a master/child relationship - representing these concepts as catalogue and inventory records respectively. The Archive, on the other hand, is effectively a collection of XML documents, and lacks a sufficient search engine.
It can be argued that these separate systems should remain separate - their primary users are separate constituencies, with quite different needs. Library systems, after all, must be built to suit the needs of visitors to the library and the management activities that are focused on the public service required to open access to those users. Object systems, on the other hand, tend to be more inwardly focused on the organization itself - with detail on the history of the object, who has handled it and when, its moves, conservation etc. These processes are more particular to the organization and its own structures, and an object database reflects this. Many would argue that it's a case of 'horses for courses' - these systems have grown in accordance with the needs of their constituencies. Any attempt to 'amalgamate' them would be too difficult and would inevitably compromise their functionality
Nevertheless there are a number of reasons for the collection to be considered as a whole. A key component of the Museum's infrastructure is the Image Library (called, for the purposes of this paper, the Digital Asset Management system or DAM) which stores records that either (1) describe and point to digital images or (2) describe Color Transparencies. Until now this system was only able to relate its contents through live links to CIS. It is clear that it needs to be able to relate its content to the entire collection through live links available to the source systems.
Moreover there are important functions within the Museum, such as Conservation, Exhibitions, Loans, Gallery Project Management, which are increasingly using IT to make their processes more efficient, and which have a vested interest in regarding the collection as a whole in terms of their information requirement. These users are invariably working with lists of objects that may traverse the three source systems. For example, conservators working on a group of objects for a loan will need consistent information about the objects (such as name, dimensions, etc.) to which they may add further information, such as the materials used during the conservation process, the date of the activity, time taken etc., for each object. Such information has high value in terms of forming historical records of the activities surrounding an object. The source information about the object could potentially come from any of three separate systems, and the problem is compounded given that the different systems present their data differently.
In such a case, as none of the systems provide information in the way the end user wants it, the risk is that further systems will be built without sufficient interface to the source systems, and products such as MS Access, Filemaker Pro and even MS Excel provide tools that can provide quick-fix applications that appear to improve productivity. In reality, so much time is spent on transferring information from the source databases and maintaining it that any efficiency improvement is eliminated - and in some cases, further resource is required simply to maintain the new desktop system. Moreover, the information captured by these systems is often of high corporate value, which is not borne out by the capabilities of tools which are deficient in their ability to provide robust maintenance and accessibility. MS Access, Filemaker and Excel are not designed to provide mid to long term store of corporate data, and are not sensible solutions where multi user access is required.
At the V&A, perhaps like other Museums and Galleries, this problem is becoming increasingly prevalent. We have tried to address it by building on the success of the British Galleries Project and experimenting with harvesting records from one of the source systems into a shared table. Harvesting is a term given to an automated routine (typically carried out at the end of each day) whereby data from one database is copied into another. In this way the harvest is intended to keep the two databases in synchrony with each other in respect of the records in the source. This information has been made available to a custom designed conservation application based on an Oracle platform, and has alleviated the problem of information management.
However, a number of issues persist:
- Because the harvest is based on just one of the source systems, records required from the other systems have to be entered manually.
- The harvest takes only 10 fileds from the source system.
- The harvesting process itself takes time to run (4-5 hours each night), and potentially will take longer if more objects are added to the source system, or if further fields were required.
- The harvesting process is itself an additional maintenance overhead.
- The IDs contained in the shared table have (mistakenly) become used by the target applications to uniquely identify objects.
The final problem, which we could put down to our 'learning curve', reflects the confusion that can arise when a source system is challenged on its status as the mastering system: the IDs that should have been used were those that exist in the mastering system, not those which are 'artificially produced' during the harvest process.
Conservation was highlighted in the case study above as a department that needs to see the collection as a whole, but it is by no means the only department in this position. The Visitor Services department is continually dealing with questions from the public about objects across the entire collection, and it would be useful if staff there could provide this information without having to look up separate databases (which themselves require specialist knowledge). Exhibitions and Loans are also dealing with objects from throughout the collection. Their handling of objects and the increasing requirement that objects be more available to the public (often involving moving objects across continents) suggests that they too must record their activities at a level which addresses the collection as a whole.
Gallery projects are responsible for managing internal decants and restructures, and must also use information about objects from throughout the collections as they move objects around, trial and design new locations for objects (often working with external agencies), and build multimedia interactives that make use of public access descriptions. Similarly the Web team is charged with providing content about objects in many different contexts, often as groups of objects that are to be associated with a particular theme or idea. The groups span the entire collection. Recently considerable interest has been directed at the need to repurpose content for potentially different output mediums, such as for gallery interactives, for Web users (given various profiles), for handheld devices, and even for mobile phones. Obviously XML has a role to play in managing such content.
2.1 The Needs
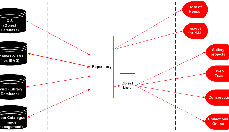
The requirements of each of these user groups within the Museum are characterized by a need for access to information from source systems for list or groups of objects. Fig. 1 shows an idealized summary of the source systems and the potential applications that would use them.
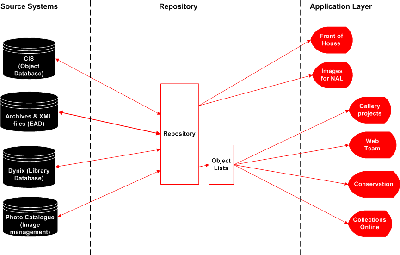
Fig 1: Diagram of the idealized system.
The problems that this case study has highlighted can be summarized in the following set of generalized requirements:
- Data must be mastered (entered and maintained) in one place only (using the principle of 'write once, publish many times').
- The identified source systems which provide rich functionality to their respective communities should not be compromised.
- Information from all three source systems, in addition to the Image Repository, must be made available to a variety of applications, preferably the client, in a consistent format.
- Information so provided must be up-to-date.
- Not all of the applications will require all of the data.
- Because of our experience a solution that involved harvesting, or 'ETL' (Extract Transform and Load) into a 'Data Warehouse' is not a preferred way forward.
3. Finding a Solution
It was agreed that in order to build the infrastructure (i.e. the repository and its interface into source systems), two simple applications would be built as 'proof of concept'. These were (1) the 'Front Desk Application', a querying portal that would allow Visitor services staff on the front desk at each of the sites to look up objects on the basis of public enquiries and identify their location; and (2) a portal that would supply images to the NAL Internet portal. The fairly simple requirements of these two systems would serve as reference points throughout the process of system build.
At an early stage, we sought the help of an existing supplier, System Simulation Limited (SSL), the supplier of our CIS system, who were suitably excited by our initial ideas.
3.1 Part 1: The Systems Architecture.
Leaving aside for the moment the problem of aggregating records from the source systems, i Requirements 2 and 6 suggest that the solution involves implementing a form of virtual repository - a repository that is defined in terms of the source systems, but not actualized. Requirement 3 suggests that information be made available using XML, the language which is synonymous with repurposing content. The obvious technology that combines these two into a viable solution is Web Services as defined by W3C (See http://www.w3.org/2002/ws).
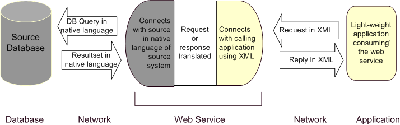
Fig 2: Anatomy of a Web Service
The diagram in Fig. 2 shows how a Web service works in summary form. The calling application (on the right) has to know what data it needs, so it formulates its call in XML, creates the document, and sends it over a network to the Web service using (normally) the http protocol. The Web service receives this as a request and reformulates the request in the native language of the source database, which could be 'SQL', an API call, or a call using the 'Z39.50' protocol - anything is possible, depending on the native language of the source system. The data retrieved by the source database is then sent back to the Web service layer, which duly creates an XML document that is sent back (over a network) to the application. Note this procedure could be extended to include updates or append operations for databases.
The protocol that is used for communication between the calling application and the Web service is a W3C standard called SOAP (simple object access protocol). SOAP is an XML-based messaging mechanism which is platform and programming language independent. It enables exchanges of structured and typed information in a distributed environment (i.e. peer to peer) across the Web. SOAP thus moves across transport schemes such as http (or indeed RPC, TCP, SMTP etc), essentially allowing an exchange of XML documents to take place.
Typically, Web Services are not only platform and programming language independent, but also self-describing and potentially self-advertising (for a discussion of the latter feature in the form of 'UDDI' - Universal Description, Discovery and Integration - which is a directory mechanism that allows the registering of Web Services, see Gurugé 2004, pp 15-16 and 145-148). Web Services describe themselves using an XML format called WSDL (Web Services Description Language, see http://www.w3.org/TR/wsdl). The goal of WSDL is to offer a structured means by which any Web service is sufficiently defined (in XML), and as such it is capable of publishing a definition of itself (i.e. the particular service it provides) that can not only be examined by any interested third party, but can also be examined by automated processes which wish to link to the Web service. As in object oriented programming, these applications do not need to know how (or where) the Web Service is actually implemented. That means that a user of a Web service (who might be designing an application that accesses this service) can consult the service's WSDL for a sufficient description of how the service is implemented, i.e. how the request document is formed, the format in which the response will be made, and indeed how requests can be structured. In other words, the documentation is an intrinsic part of the service.
So, returning to the Museum situation, if a team had commissioned a third party agency to build a multimedia display for a set of objects in an gallery project, as an interactive complement to the visual display, a Web service could be set up to give access to the underlying content (stored in the source database). The agency would be able to examine the service's 'WSDL', enabling the system to be built around calls to the Web service without having to consult documentation of the database system or indeed the data model - this would be clear enough from this layer or documentation provided by the service itself. The captions for the exhibition objects or public access descriptions could be prepared and signed off by curators and educators on the source database, and the agency designing the interactive would have the means to easily build this data access into an application. If all of the required content were exposed by Web services, the code for the interactive could be minimal and might not require the setup of further databases with resultant n-tiered development (for more information about a generalized model for Multimedia Interactives, see Croxford and Solomon (2004, p.219). This means more of the agency's effort could be directed at issues such as usability and design. Moreover, because the Web service publishes XML, the same content would be available to other applications which could easily repurpose it for the Web, for handheld devices, and even for emerging technologies like SMS servers (mobile phones).
Web Services deployed in this way give Museums and Galleries a way to standardize records and their underlying information in a conceptual repository that is separated from the source systems, making this information available to light-weight applications. The Web Services layer simply rationalizes the management of the core information component of the Museum's systems architecture.
3.2 Part 2: the Common Data Model
A second key task in providing a solution is to establish a standard way for aggregating the records of the source databases: that is, to make decisions on the terms on which selected fields in the three source systems might be deemed equivalent for the purposes of aggregation.
In our case study, the approach taken was to agree on the structure of a 'Common Data Model' among a working group of experts in the three systems: CIS, Horizon and the Archive. The requirements of a querying portal that would form the basis of the Front Desk Application by Application desk were used to focus the discussions on aggregated data items that such an application would require. By using an actual scenario that the three experts could relate to, we enabled the discussion to be solution oriented rather than abstract and theoretical.
An important problem that had to be overcome is that the different structures of the systems created separate models for search and retrieval. In the NAL system, because of the way that indices are used for search operations, field level definitions of search and retrieval operations differ. This distinction needed to be considered for each of the fields in the Common Data Model. The Archive, which is stored in XML format, also required special consideration, in that in order to retrieve meaningful information, a sufficient number of tags at a lower level of the hierarchy would be required by the retrieve operation. Thus the question, “In order to retrieve x in a given system what must I search?” had to be posed for each data item in the model.
It also became clear that it would be useful if there were a common standard to which the prototype Common Data Model could relate. Three possibilities emerged: Dublin Core, SPECTRUM (see http://www.mda.org.uk/stand.htm) and CIDOC-CRM (see http://cidoc.ics.forth.gr). Dublin Core with its 14 key fields was deemed too simplistic to gain the required level of granularity of data for the variety of applications envisaged for the project. CIDOC-CRM was a comparatively new proposal and while the current debate within the CIDOC community is relevant to several aspects of the Common Data Model, the group felt that it was insufficiently mature and potentially too dense to be its direct focus. Work had already been undertaken to map CIS to SPECTRUM, and with substantial revisions, this became the focus. Horizon and the archive were mapped and a prototype Common Data Model comprising some 97 fields has been established.
3.3 Proposed System Architecture
The diagram in Fig 3 shows the proposed system architecture.
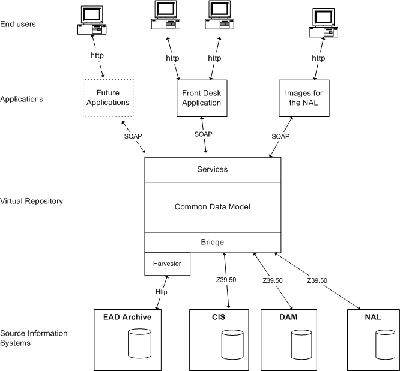
Fig 3: Proposed system architecture
In order to deliver the two agreed applications, the services required are as follows:
- Search - a standard mechanism that enables searching the three source systems;
- Retrieve - a standard service that allows access to records resulting from a search;
- Index browse - a service that allows access points to be 'browse able';
- ID Resolution - a service that allows mapping between Museum reference IDs;
- Image serving - a service that has the ability to translate from a Museum reference ID to a digital image; and
- Search Term Highlighting - a service that returns records with an indication as to which parts of those records caused the search to match.
These services form the initial stages only. As the repository is built, and the data is more widely used, the range of services will increase.
At the time of writing (Jan 2006), the project is making good progress, and the supplier has delivered some of the core components of the architecture. We look forward to reporting further progress at the conference in March.
4. Web Services for Museums and Galleries?
While this paper has described in some detail the raison d'être for the project, while offering a summary of the merits of SOA, there is a sense in which what is being suggested here has significant potential for other Museums. By this I am suggesting not only that other Museums may benefit from rationalizing their data structures and systems architectures by using the framework offered by Web Services, but also that the model of this project could be used to improve interoperability between Museum databases. That is, just as the V&A has exposed a virtual repository built by aggregating the data from very separate sources through focus on the SPECTRUM standard, it is conceivable that separate organizations could collaborate to offer their own repositories that map to the SPECTRUM standard as Web services that could be aggregated by other services or applications.
When our virtual repository is in place, it will be possible, indeed necessary in order to achieve some of the goals of our Web site, to make our Virtual Repository available as a Web Service to the Web. This means that anybody (including ourselves) would be able to connect to our services to gain access to our content and make use of it. In this way initiatives such as Scran (or the now unavailable AMICO) could get their content through a live feed to our Web service. This would ensure the content is up-to-date, and would facilitate the way we provide further records for use by such projects. Indeed there are significant advantages for such initiatives to move away from harvesting or uploading content supplied by Museums, and towards a more dynamic, easily maintainable approach whereby Museums would be encouraged to publish their content as XML based services.
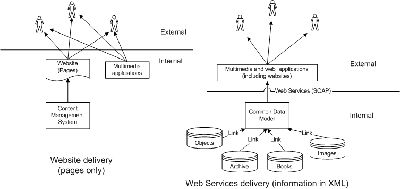
Fig 4: The 'Web' and 'Web Services' paradigms
These ideas suggest a significant move from the standard paradigm of the Web, as is suggested by the diagram in Fig. 4. The Web as it is currently structured (shown on the left hand side of the diagram) offers content that we have presented with our branding, our curatorial ideas, and our own designs, and which we are able to refresh from time to time using style sheets etc. Although it can be rendered dynamic in that the user chooses which pages to see (or for which objects to retrieve information), it is not particularly dynamic in the sense of what can be done with that content. Web Services offer the scenario pictured on the right, whereby a selection of our content (in particular, our object-related information directly from the source systems) is made available as neutral XML documents. But the architecture of the service allows end users the flexibility to use the information as they see fit. The Web Services paradigm in Fig 4 effectively proposes that the application layer be moved up the development tree, and indeed outside our firewall.
Not everybody will be comfortable with some the ramifications of what I am proposing here (and it is important to note that control of what is made available and what is not would be the domain of the service itself). But there is significant potential for powerful joined-up heritage sector applications that harness the power of the constantly evolving information superhighway.
References
Croxford, I. and Solomon, B (2004). VIA - The V&A Information Architecture. In V. Cappellini and J. Hemsley (Eds,) Electronic Imaging and the Visual Arts: EVA 2004 Florence Proceedings. Bologna: Pitagora Editrice. 216-221.
Gurugé, Anura (2004). Web Services: Theory and Practice. Oxford and Burlington, Elsevier.
Cite as:
Solomon B., Using Web Services to Deliver Information Integration, in J. Trant and D. Bearman (eds.). Museums and the Web 2006: Proceedings, Toronto: Archives & Museum Informatics, published March 1, 2006 at http://www.archimuse.com/mw2006/papers/solomon/solomon .html