
1. Introduction
Many museums have large collections that far exceed available display space. These institutions face a significant challenge in making collections accessible to researchers and the general public. In addition to digitization, they must find and deploy Web-based tools that support search, discovery, and understanding of their collections. One common approach replicates the exhibition experience on-line; these sites are often beautifully authored but are not well-suited to the tasks faced by researchers or even by many public visitors.
In contrast, many commercial enterprises are deploying state-of-the-art information management technologies that support search and discovery within their rapidly expanding document corpora. These approaches are often described as semantic search because they go beyond simple keyword matches and model semantics (meaning) in the collection using a combination of ontologies (knowledge models) and linguistic techniques. Given the size of these corpora, it would be impractical for humans to classify every document, especially since the ‘appropriate’ categories may change depending on the audience. Semantic search tools address this by automatically associating concepts to each object. Enterprises have demonstrated the utility of these tools in making ‘knowledge workers’ more productive. This is driving rapid growth in the associated enterprise search market.
While the activities of commercial enterprises are often quite different from those of museums, many information access tasks are actually quite similar. Dedicated staff use various metadata to search for particular items in a collection; visitors and general users need to understand what is available and how concepts are distributed across the collection; researchers seek to discover patterns and other knowledge within the collection. Semantic technologies support these activities particularly well, moving beyond the hit-or-miss success of keyword-based approaches and cumbersome, structured database search solutions to more powerful and easier-to-use tools for browsing and searching collections.
Unfortunately, these tools have not been adopted into the museum and cultural heritage sector due to a variety of factors, but primarily because:
- Technical talent required to develop and deploy these solutions is somewhat scarce, and most of those with the appropriate background have been snapped up by commercial vendors of enterprise search tools.
- The underlying technologies (especially for natural language processing) are optimized for standard text document corpora. These linguistic tools tend to behave poorly when applied to the terse and jargon-laden language commonly used for annotations in collections management databases.
- Adapting the existing tools is a difficult and costly endeavor for museums, and is generally well beyond their sphere of expertise. By the same token, the cultural heritage sector is not seen by commercial vendors of enterprise search tools as sufficiently lucrative to justify adaptation of their existing tools.
We have seen progress in related open source projects (e.g., Fedora, OpenCollection, steve.museum, et al.), but no semantic toolkits are available for museums. Even if natural language processing (NLP) technology were more widely available, it would have to be adapted to meet the needs and goals of museums. In addition, activity around ‘ 2.0’ and emphasis on community is pushing museum sites to move beyond the typical on-line exhibit model and to provide collections explorers with support for personalization and sharing.
Recognizing these problems and having a strong interest in the cultural heritage sector, a group of graduate students at the U.C. Berkeley School of Information created Delphi – an open source toolkit that combines state of the art tools for NLP and ontology-based faceted browsing, together with ideas from social media sites (e.g., Flickr, Digg, et al.). The toolkit was developed in close collaboration with staff at the Phoebe A. Hearst Museum of Anthropology (PAHMA) at U.C. Berkeley, and was deployed for the Museum’s collections. After a period of staff review and additional usability testing, the associated site was updated and launched in early 2008. Delphi is freely available under open source license, and we hope to build a community of museums and technologists that will facilitate its wider deployment.
The next sections provide some background and context for the development project, an overview of the Delphi toolkit and technologies, and our deployment experience with the PAHMA collections. We close with a discussion of ongoing and future work around Delphi and the PAHMA collections browser.
2. Background And Related Work
2.1. Museums Context
In an era that has witnessed calls for the increased transparency of, and more freely available information from, cultural heritage museums, such museums have increasingly come to regard on-line collections accessibility as one means of making substantial progress towards these goals.
For museums wishing to let the on-line public explore their collections, however, the avenues towards this goal, as well as the tools needed to implement them, are limited. One common approach used is to create on-line exhibitions - a task for which many tools exist, notably the open source toolkits created by the Omeka (http://omeka.org) and Pachyderm (http://pachyderm.org) projects. In fact, many museums depend exclusively on on-line exhibits as a means of exposing their collections to an on-line audience (e.g., National Museum of the American Indian, http://www.nmai.si.edu).
While the didactic and aesthetic value of these on-line galleries argues for their being an important element of the museum’s educational mission, the experience of a narrated, linear progression through a series of carefully selected objects that such on-line exhibits offer is no substitute for an individual’s untethered, self-guided exploration and discovery of a museum’s collections. Such on-line exhibitions do not give the users the freedom to explore museum objects in ways that make the most sense to them, nor do these sites fulfill the aims of curiosity, research, or casual interest that brought them to the museum’s site in the first place.
Two current options available to museums are publishing tools that integrate with a museum’s existing CMS (e.g., eMuseum paired with TMS, both by Gallery Systems), or stand-alone content management systems that allow visitors to query catalogued metadata to find information and images of interest. Such on-line collections databases represent a large step towards the goal of accessibility, but they still leave a lot to be desired for a non-specialist target audience because searching is almost always based on simplistic keyword- and field-based queries.
Both of these options suffer from many of the same problems that internal cultural museum databases suffer from. These systems, commonly based on direct transcription of historical paper records, force the unsuspecting public to read the minds of the last two hundred years of anthropologists and force users to follow antiquated classification systems. For searches in such a system to return meaningful, accurate, and reasonably comprehensive results, the users must know what they want to find and how to go about finding it. This is more complex than it sounds, and the quality of the results obtained depends on several factors. The role of these factors is best illustrated with examples.
Best search results often rely on knowledge of how experts in the field refer to, and have historically referred to, the object or subject in question. For example, someone looking for an example of a Papago basket similar to the one their grandfather had collected would need to know that the term ‘Papago’ has now been largely replaced by the term ‘Tohono O’odham,’ and so queries will need to be run on both terms. In addition to such simple term substitutions, the user must speculate as to how objects with specific names in one field may have been catalogued by experts (or even non-experts) in related fields. For instance, a type of object commonly sought at PAHMA is referred to as a ‘donut stone.’ While much of the collections at PAHMA were catalogued and documented by experts, terminology varied according to the research perspective of the cataloguer. In order to find these ‘donut stones,’ a user would need to search for ‘stone’ and/or ‘rock’ in association with ‘round,’ ‘hole,’’“perforated,’ ‘net weight,’ ‘digging stone,’ or ‘charmstone’.
Another problem is that simple keyword-based searches often work quite poorly. For instance, a user wishing to find examples of plates (for food) might search on ‘plate’ and be surprised to find silver plated objects, printing plates, plates of engravings, fashion plates, plate armor, plate racks, photographic plates, as well as plates meant for food. In fact, a search for ‘plate’ at one cultural museums site with 82,000 searchable objects returned 7,470 results, nearly 10% of their total collections.
Most of these issues can also be addressed with extensive data cleaning, normalization, etc. This may be viable for an on-line exhibition with a few hundred objects, but scaling this to every item in a museum with tens or hundreds of thousands of objects would entail years-long delay in making collections accessible to the public.
Another consideration relates to the changing focus of scientific research at museums from traditional descriptive endeavors to more synthetic and integrative research avenues. This shift is resulting in greater numbers of researchers bringing broad and seemingly vague requests to museums: prospective researchers might “want to compare objects made of hard woods to those made from softer wood” or “want to look at depictions of children through human history.”
A few cultural heritage institutions are exploring newer technologies for on-line collections browsing. Most notable among these recent offerings is the Smithsonian’s SIRIS project (http://siris-collections.si.edu/search), which incorporates a faceted browser to facilitate navigation and discovery of the contributing institutions’ collections. SIRIS is still evolving to address usability issues and improve the user experience, and it should be noted that it is not an open source project nor otherwise available for wider use.
2.2. Academic And Enterprise Context
The Flamenco project (Yee et al., 2003) described a faceted browsing solution for image collections, and included tools to help extract the facet metadata that underlies the UI. We built upon many of the ideas in Flamenco, although we took a somewhat different approach to defining the ontology. In particular, many of the concepts were either fairly specific to the domain (e.g., specific types of baskets, types of ancient coins, and names of Native American tribes), or so general as to defy simple word labels (e.g., figurative designs featuring a flower). Because of this, we were not at all confident that WordNet or other thesaurus resources would be very useful.
Many commercial sites (e.g., Buy.com, Cnet.com) have begun to feature simple faceted browsers, further demonstrating their utility for search and discovery. However, most commerce sites have only a single, flat list of choices within each facet (this has also been called “parameterized search”). In part this is because their ‘collection’ consists of at most hundreds or a few thousand objects. To cover the breadth and depth of PAHMA’s millions of objects, we needed a more complex ontology, and more sophisticated support in the faceted browser.
Many commercial vendors of enterprise search tools (e.g., Autonomy/Verity, Convera, FAST, et al) leverage statistical and NLP tools, and support faceted browsing or similar semantic search UI. Many of these vendors provide much more sophisticated technology for question answering as well as support for enterprise document management, most of which is out of the scope of a museum collection’s browser solution. As mentioned above, these tools are expensive and otherwise unsuited for this application, but the general approach served as inspiration for the Delphi toolkit.
There are a number of open source NLP toolkits available (e.g., OpenNLP, NLTK), but like the enterprise tools, these concentrate on complex parsing of standard business text and machine learning techniques appropriate to large text corpora. A museum’s application called for something lightweight and adapted to the linguistic constraints of collections annotations, with the tools to support faceted browsing.
The OpenCollection project (http://www.opencollection.org) provides a -based interface for collections management, but does not currently support browser functionality well-suited to the visiting public. In this sense, Delphi is a natural complement to OpenCollection, and we are considering a closer integration of the projects.
2.3. Social Media Tools
Social media tools have been shown to be very effective for generating and supporting the community around a media collection. The rapid growth of social media tools like Flickr (http://www.flickr.com) and del.icio.us (http://del.icio.us) demonstrate the broad interest in these models, and some museums have already begun to leverage similar ideas. Libraries and Archives Canada (Greenhorn, 2005) has seen good success with this approach, and the Library of Congress recently began an experiment placing images from their collection on Flickr to generate annotations (Raymond, 2008).
The most successful social media models focus not on media but on community, and how people want to use, reuse, and share media. While the steve.museum project provides open source support for tagging, it has not emphasized the sharing and community features that have made Flickr so successful. Research at Yahoo! (Shaw & Schmitz, 2006) described the value of a research framework for community annotation of media to support analysis of annotation activity. Unfortunately, this is not available as an open source toolset.
3. Our Solution
Delphi is an on-line browsing and searching system that can be used by researchers, students, and educators to explore diverse museum collections. The interface helps a user discover and understand “what’s there.” Delphi’s features support searching, browsing, viewing information about objects, creating and viewing sets of objects, and annotating objects in the collections.
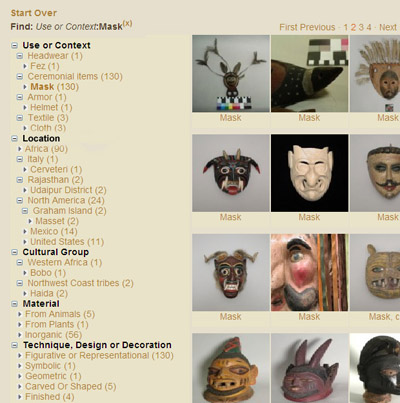
Fig 1: The Delphi faceted browser
The Delphi faceted browser provides a simple way to navigate through museum collections (Figure 1). The browser view changes dynamically to show only categories relevant to the area of the collection that is being explored. This makes the browsing experience more visually streamlined and helps the visitor discover categories and relationships between objects that may not otherwise be obvious. Clicking on any category refines the search. The category listing on the left is derived automatically from an underlying ontology that organizes concepts associated with the collections into distinct facets such as location, culture, materials, etc. Concepts are associated to each object in the collections by text mining - applying linguistic tools to text metadata from an existing content management system.
3.1 Delphi Toolkit Overview
The Delphi toolkit provides:
- a suite of text analysis and processing tools that support development of ontologies and perform text mining,
- a data model and associated services to support collections browsing, and
- a presentation architecture that is easily customized to match the style and layout of a given institution’s site.
At the heart of the toolkit are the tools for text analysis and processing. These read in existing metadata (i.e., text fields associated with the objects in the collections) and analyze the vocabulary in use as a guide to the design of ontologies. Once an ontology is defined, additional linguistic tools process the metadata to mine concepts from the text, associating categories in the ontology with each object in the collections. The tools also use the knowledge models in the ontology to infer additional concepts. The results are stored in a database and are used to support search and exploration tools in a browser.
3.2 Analysis And Vocabulary Tools
A typical deployment will begin by using statistical analysis tools that describe the common vocabulary used in the metadata for a collection. The metadata itself are read from a simple text file, as comma- or tab-separated values that correspond to selected columns in the tables of a collection management system. These could also be selected columns from a spreadsheet or other simple tool that collects names, notes, descriptions and other data about each object in the collection. The contents of the file are fairly arbitrary - any column that has data useful for exploring or browsing the collection can be included. This ‘dump file’ is easily exported from a variety of tools. This approach allows Delphi to work with a wide range of collection database solutions.
A column configuration file is created to describe the contents of the dump file. This simple XML file specifies the name of each column and some basic rules about how to interpret the column text. An important class of rules defines characters and strings that separate meaningful tokens in the text (commonly semi-colons, periods, etc.). The Delphi tools first scan the column configuration file, and then use the rules to import the metadata dump file.
Having imported the dump file and parsed the contents into tokens for each column, a useful function generates a report of the vocabulary used in each column, sorted in descending order of usage. This effectively identifies the key concepts that are used to describe objects, and so provides an indication of what concepts should be present in the ontology used to browse the collections.
3.2.1 Defining The Faceted Ontology
In some cases, existing common ontologies (or taxonomies or controlled vocabularies) may be leveraged for some facets (e.g, culture, location). However, depending on the collection, existing resources may have to be extended to reflect the vocabulary used by the museum (e.g., the place names referred to in a provenience column). In addition, since the ontology is used to derive the faceted browser UI, the structure and concept labels (aka primary terms) should be chosen with the end-user of the system in mind. An ontology (such as Getty’s AAT) appropriate for museum staff may be much less useful or meaningful to visitors. This issue of point-of-view in ontology has broader implications that are discussed in some detail in the full deployment report (Amuzinskaya et al., 2007).
The facets in an ontology are distinct and independent qualities. Separating these from one another simplifies the overall structure and makes it easier and more powerful to use for searching and browsing. Following classic principles of faceted design (Ranganathan, 1945; Soergel, 1974), the PAHMA team chose facets that address the general questions of ‘who?’, ‘what?’, ‘where?’, ‘when?’, ‘how?’ and ‘why?’ for museum objects.
An important step in the development of the ontology is the addition of linguistic features including synonyms (equivalent terms), and exclusions (terms that help disambiguate different meanings). This aspect of the ontology is a significant determinant in the overall quality of the search and browse experience, and thus is worth the required effort. In practice, however, it is an ongoing process that continually improves the results. The ontology is described in a simple XML format.
3.3 Text Mining And Inference Engine
The Delphi text mining tool uses an ontology and the metadata dump file to perform the text mining step (also known as categorization or semantic indexing in some enterprise search tools). The tool processes objects one at a time, filtering ‘noise’ out of the text and then checking for the various terms associated to concepts in the ontology. Although the details are more complex, it is essentially an elaborate exercise in matching text strings and then checking for constraints to disambiguate among multiple meanings.
A common problem encountered in text mining is that a given word can be used in various contexts. It may have multiple meanings, as in the case of “jaguar”: it can be an automobile, an animal, or a computer operating system. Words may also have the same meaning but be used in different ways. For example, the word “deer” is primarily used to denote a particular mammal. However, the PAHMA collection has many objects that are deer bones, and others that feature a representation of a deer as a design or motif. The PAHMA ontology has one facet for materials and another facet that includes designs. We want to recognize the design context without getting the deer bone objects mixed in. To achieve this, we use the idea of entailment phrases, such as “figure of an X” or “X motif” as a means of recognizing the sense we are interested in, and then apply these to an entire group of concepts. This makes it much easier to describe and maintain the ontology, but yields a very rich set of synonyms and improves the quality of the search results.
Another feature of the ontology is support for inference rules that model knowledge about the domain (e.g., about anthropology in the PAHMA deployment). A simple case involves inferring broader categories from narrower ones found in the collections’ metadata (e.g., associating Africa with objects that come from Ghana). However, we can also incorporate domain knowledge into the ontology. As an example, for all objects that are a kind of mask and that are made of wood, we can infer with reasonable confidence that the technique used to produce the objects was carving. It is common for annotators to omit common-sense details like this, but the omissions make it harder for users to find items by different criteria (in this case, by technique). Inference rules can greatly enrich the existing metadata and improve the search experience. The inference rules can be time-consuming to create, but can be added over time to improve the results.
3.4 Faceted Browsing Support
Each time a user clicks on a category to further refine a query, the service must translate the list of categories (plus any keywords from the initial search) into an efficient SQL query. For many categories, this becomes a deeply nested query that can be time-consuming for the database engine to compute. We developed a method of re-ordering the categories in such as way as to optimize the query process: this significantly improved performance (reducing page response times by a factor of five to ten).
Once a set of results has been produced for the current query, additional database queries determine which categories are associated with the current results set. However, this set of categories often numbers in the hundreds. Delphi then applies heuristics to filter the categories for each facet down to a short list that summarizes the results and that also provides optimal refinement choices. This process must also ensure that the user is given sufficient context to understand the categories. For example, if all the results happen to come from within one area, we could just list the different cities for the set. But city names are far from unique, and may also be unfamiliar to some users. Without the state name (in the U.S.) or the country name (for other countries), users lack sufficient context to understand the categories. On the other hand, users do not need to see North America, United States, or Western Region as context for California. Including these additional categories would clutter the user interface.
3.5 Social Media Support
We conducted an in-depth needs assessment of the functionality around media sharing and personalization. The resulting design allows users to gather items from the collection into personal sets around a given theme. Users can name each set, and then also add a note for each item, describing why it is in the set, creating narratives around their interests. They can then share these sets with others via an e-mail form, thereby drawing others to the museum.
We have added simple tagging support, and continue to explore how best to integrate this with the existing semantic index on the collection. An open question remains as to whether users prefer tags to behave like additional keywords in a unified search model, or whether they want tags to function as a separate mechanism. Another issue is whether users would want to leverage tags from the whole community or just use their own tags when searching.
3.6 Media Processing And Handling
We wanted to support detailed visual exploration of collection objects, but the Museum also wanted to protect the intellectual property rights to their high-resolution photos. Our solution was to convert the high-resolution images to tiles that support a zoom-and-pan applet on a details page for the object. This makes it very difficult to ‘steal’ the high-resolution photos, but still provides detailed views. The initial version of Delphi uses off-the-shelf solutions to produce tile- and thumbnail-image derivatives, but this will likely be replaced by an open source variant such as that in OpenCollection.
Although many users will focus on objects with images, nothing in the system depends on having images. The majority of the PAHMA collections have no images associated with the objects, but the browsing and back-end functionality works equally well, allowing researchers and others to discover and appreciate the full extent of the collections.
3.7 Web Presentation Layer And Templates
Delphi defines a simple presentation data model and a set of customizable HTML templates for generating the page content. These templates (and associated CSS stylesheets) define the presentation and visual design, separated from the logic of how to get the information for the faceted browser, the object details, etc. This makes it very easy to adapt the visual design to fit the ‘branding’ for a given institution, including logo graphics, general layout, color and font schemes, etc. Between the alpha and beta versions, PAHMA’s Delphi site underwent a significant visual redesign simply by changing the templates, stylesheets, and some images.
4. Deployment Experience At PAHMA
The PAHMA deployment of Delphi was targeted at a broad audience of users with the aim of raising public awareness of the Museum and the depth and breadth of its collections. It was hoped that the Delphi browser would improve access to the Museum’s collections for many different types of users: curators, collections managers, researchers, university students, K–12 students, teachers, avocational ‘hobbyists’, history buffs, casual Internet browsers, potential Museum visitors, and heritage communities were among those who stood to benefit from the addition of the Delphi browser to the Museum’s presence.
Museum staff hoped to serve all of these audiences equally well, but such a broad mandate was understood to be an unrealistic goal for the initial deployment of the Delphi browser. The Delphi team undertook an extensive needs assessment to identify the primary audience to target in the initial deployment. Over the course of several months, numerous interviews were conducted with Museum staff, university faculty and students, K–12 educators, visitors to the Museum, researchers visiting the collections, as well as members of the Berkeley community, some of whom were unaware of the Museum and its collections.
Following the tenets of the User-Centered Design (UCD) philosophy, personae were defined to represent sample members of each target audience, and a task analysis matrix was compiled for each of these personae.
The results of these analyses demonstrated that there were considerable areas of overlap among the various target audiences - overlap that could be optimized with a strategic choice of target audience. This finding, paired with the Museum’s stated goal of raising public awareness of the Museum and its collections, led to the selection of “enthusiastic public visitors” as the primary target audience. Given the overlap in requirements and preferences, much of what was designed to best serve the primary target audience would also end up serving the other audiences. In this sense, the primary target audience was not the sole audience for which the PAHMA deployment of Delphi was designed. Rather, the deployment was intended to serve many, if not all, of these audiences. Where serving multiple audiences created design conflicts, the needs of the primary target audience drove the final decision.
The User-Centered Design process guided both the information architecture and the visual design of the Delphi collections browser. For instance, to present a friendly and inviting interface, the front page features items and sets that beckon exploration. To avoid overwhelming the beginning user, the faceted browser is initially hidden, and exploration of the collections begins with a simple and familiar search box. This simplified search model then leads the user to an initial results page where the faceted browser is revealed.
These and other design choices were made to best align the initial PAHMA deployment to its primary target audience, but Delphi can be configured to model many different classes of users, each coming to Delphi with a specific point of view, special requirements, and certain limitations. Most users will see the default view, but qualified users can be presented with alternate views, varying the user interface, the facets chosen, access to different or additional types of data, as well as different levels of administrative or editorial access. For instance, an object’s catalog number was argued to have little value to casual browsers and thus was hidden in the default view. The same number is critically important to curators, collections managers, and researchers, and therefore is visible to them.
An open question of considerable concern to PAHMA staff is the potential for rapid increase in researcher activity and requests to examine the original objects. The Museum decided to accept that risk, given the potential benefits.
One final consideration for any museum planning to expose its full collections metadata to a broad audience is that increased visibility brings with it potentially increased scrutiny, thus requiring increased efforts to review collections metadata for potentially embarrassing or sensitive content.
5. Future Work
5.1. Planned New Features
We are continuing to improve and refine the text-mining engine to better recognize concepts and to support finer-grained relevancy ranking of the category associations. Other features we want to explore include automatic recognition of likely misspellings, and co-occurrence modeling to recognize alternate terms for a given concept and to suggest potential inference rules.
As we refine the heuristics that filter categories to produce the faceted browser for a set of results, we have identified several concepts that we want to introduce into the ontology to improve the user experience.
- First is the notion of the generic concept, i.e., one that is widely understood on its own, without qualification or context. For example, for a location facet, the level of U.S. state names (California, Michigan, etc.) needs no further context for most of the primary audience. Below this level are counties, cities and more detailed locations that require the generic context in order to be widely understood.
- A related concept is a specific concept, or one that denotes the level of detail beyond which the average lay visitor is unlikely to understand or appreciate. Taking another example from the location facet, we might mark cities and towns as ‘specific’, and then hide additional details like archaeological site designations from all but museum staff and researchers.
The level of generic and specific concepts varies among facets, and is also a function of the audience’s point-of-view. However, we think that marking these levels in the ontology will provide a valuable tool to improve the faceted browser interface, and to allow for effective adaptation to different audiences.
Following the model described in Shaw & Schmitz (2006), we plan to use the activity of users in the system to provide additional functionality around sets. For example, we can detect when a given set shares many objects with other users’ sets, and can then suggest other objects of potential interest (somewhat like collaborative filtering). We can also track the community’s interest in particular objects or areas of the collections by analyzing user activity such as set definition, sharing and viewing, tagging activity, etc. Knowing objects and areas of widespread interest, the system can recommend areas of exploration to new site visitors, and could inform staff priorities for digitization work in the collections. With the right metadata and activity-tracking framework in place, these kinds of tools are relatively easy to develop.
5.2. Deployment Initiatives
We are in discussion with other museums about deploying Delphi for their collections. There has been some related interest in the potential for cross-collection search support. This raises issues of point of view: typically, a common (or translated) ontology is used for the combined collections. Alternately, various points of view might be supported by indexing a ‘foreign’ collection using a ‘local’ ontology.
Related to this are the issues of ontology reuse, and the sharing of common facets. Some facets are more common across disciplines (e.g., location and time), whereas others may be more tied to a given collection. For example, technique for anthropology is not the same as for art history, and the intersection of culture facets might be very small for collections from quite different museums.
On a practical level, the Delphi team and the OpenCollection development team are currently exploring an integration of the two toolkits to make it easier for museums to deploy a collections browser based upon their CMS.
5.3. New Research Initiatives
We have described the process of ontology design and refinement as a process more than a task, one that benefits from domain expertise (e.g., recognizing that when an object has two particular qualities, a third quality can be inferred). However, what is lacking is a tool and an associated workflow that will simplify this, and make it possible to engage a community of people in maintaining the ontology. We have proposed a model for community maintenance of curated resources (like ontologies), a model that combines many of the qualities of other community production efforts, but is adjusted to allow for submissions/suggestions to be vetted by domain experts. This allows the process to scale, leveraging a relatively large pool of graduate students, academics, and others in a given discipline who can suggest additions and improvements. However, by filtering all suggestions through a set of experts, the collections managers can still ensure that high quality is maintained.
This model will be supported by a set of -based tools to ease the process of submission and review. The tools will also automate the integration of changes into the ontology and will update the semantic index that supports the collections browser. In addition, the framework will maintain metrics for the participants over time to track how often their suggestions are judged to be correct, and as well how useful the suggestions prove to be. These factors will be combined to rank new suggestions, ensuring that the experts who filter suggestions can concentrate on the highest quality suggestions first (recognizing that they have limited time for such work).
We think that such a tool has wide application for ontology maintenance, as well as for other curated resources like specialty dictionaries, etc.
6. Acknowledgements
We would like to thank Ben Kacyra and the CyArk project for providing server resources for early development of Delphi and the PAHMA deployment. We would like to acknowledge Prof. Ray Larson, U.C. Berkeley School of Information, for his advice on the project, and the additional development team members: Olga Amuzinskaya, Adrienne Hilgert, Jon Lesser and Gerald Yu, as well as Natasha Johnson and the many other PAHMA staff members who contributed to the project.
7. References
Amuzinskaya, O, A. Hilgert, J. Lesser, P. Schmitz, and G.Yu (2007). Delphi - An online museum collection browser. http://www.ischool.berkeley.edu/files/DelphiFinalReportLinked.pdf (Accessed January 25, 2008).
Fedora Project. http://fedoraproject.org/ (Accessed January 25, 2008).
Greenhorn, B., Project Naming: Always On Our Minds, in J. Trant and D. Bearman (eds.). Museums and the Web 2005: Proceedings, Toronto: Archives & Museum Informatics, published March 31, 2005 at http://www.archimuse.com/mw2005/papers/greenhorn/greenhorn.html
Ranganathan, S. R. (1945). Elements of library classification. N. K. Publishing House.
Raymond, M.(2008). My Friend Flickr: A Match Made in Photo Heaven. http://www.loc.gov/blog/?p=233
Shaw, R. and P. Schmitz (2006). Community Annotation and Remix: a Research Platform and Pilot Deployment. http://portal.acm.org/citation.cfm?id=1178761
Soergel, D. (1974). Indexing languages and thesauri: Construction and maintenance. New York: Wiley.
Yee, K-P., K. Swearingen, K. Li and M. Hearst (2003). Faceted metadata for image search and browsing. Proceedings of ACM CHI, 2003.