
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Archives & Museum Informatics
158 Lee Avenue
Toronto, Ontario
M4E 2P3 Canada
info @ archimuse.com
www.archimuse.com
| |
Search A&MI |
Join
our
Mailing List.
Privacy.
published: April, 2002
® Archives & Museum Informatics, 2002.
![]()

Exhibits on Demand – Project Goals and Approach
Joan C. Nordbotten, University of Bergen, Norway
Abstract
Museums world-wide are deploying both virtual exhibits and multimedia collections for use by researchers, educators and the general public. With today’s technology, users searching for thematic information from multiple autonomous sites must perform a series of separate processes to locate a reference list to relevant sites, search each site for relevant information, extract relevant data, and construct a local collection for ‘off-line’ development of an integrated presentation. The users’ problem can be summarized as a need for methods and tools to assist in locating, accessing, and extracting relevant information from multimedia, multi-database systems developed and maintained by autonomous museums.
Two principal problems hinder support for location and access to multiple data sources. First, there is a lack of agreement on how semantically consistent metadata for description of data collections should be created. Thereafter a user-friendly query language and processing system must be developed to support the formulation of search criteria, search in a multi-database space, and integrate and present the search results.
This paper presents the motivation, goals, and approach taken for a newly started project that aims to develop methods and tools to address these problems by integrating and extending existing methods and tools developed separately for metadata, multimedia, and multi-database management. The primary goal is to develop a system to support dynamic generation of specialized collections as the result of an easy-to-use query language to multiple museum collections, i.e. a system to support exhibits-on-demand.
Keywords: Virtual exhibits, multimedia database management, metadata, Information retrieval, Query processing
1. Museums on the Web - an informal report from the perspective of information retrieval
Museums world-wide have been deploying virtual exhibits onto the Web since the mid 1990s. The basic structure used for virtual exhibits is a set of Web pages consisting primarily of text, images, and links from either the text or images to similar pages or image enlargements, respectively. Virtual exhibits are frequently large, often much more than 100 pages. Given that usage studies of virtual exhibits have shown that the average viewer of an in-house PC-exhibit selects less than 20 pages (Yamada, 1995 and Shneiderman, 1989), while a study reported by Nordbotten (2000) found that visitors to a Web-based exhibit selected, on average, less than 10 pages, most virtual exhibits contain far more information than an individual visitor will select.
Most virtual exhibits are self-contained in the sense that a viewer can select only the predefined exhibit pages using predefined links. In some exhibits, for example the “Bhutan Exhibit” at www.bhutan.at, a keyword search facility has been included to aid the viewer to find specific information within the exhibit. If we assume that the purpose of implementing a virtual exhibit is both to inform and to arouse curiosity about the topic, than the self-contained exhibit may not support the later goal, since there is generally no support for retrieving additional information from outside the exhibit page set.
Many museums, in addition to deploying virtual exhibits, have also made electronic versions of (some of) their collections accessible from their Web site. This makes large quantities of information available to researchers, educators, students, and the general public. However, the electronic collections are not commonly accessible from the virtual exhibits unless the Web site navigation bar contains a link to the collections and is constantly available to the virtual exhibit visitor, as done in the Web site of The State Hermitage Museum at http://www.hermitagemuseum.org/html_En/index.html.
A few examples of electronic museum collections, showing diversity of content themes, include:
- The National Library of Australia’s site, “Picture Australia”, at http://www.pictureaustralia.org/, contains numerous sets of pictures clustered by theme,
- TAMH: Tayside A Maritime History, at http://www.tamh.org/, contains a rich set of documents on trade.
- The Sculpture
Center's Ohio Outdoor Sculpture Inventory, at
http://sculpturecenter.org/oosi/oo.asp, contains an inventory of Ohio sculpture - The Virtual Herbarium of The New York Botanical Garden at http://www.nybg.org/bsci/cass/, consists of a detailed, formal classification of plants.
- The Smithsonian American Art Museum in Washington DC, at http://americanart.si.edu/study/, provides a wealth of images of American art.
The State Hermitage Museum, St. Petersburg, Russia, gives an extensive presentation of the museum and its collections at http://www.hermitagemuseum.org/html_En/index.html.
Various search tools have been made available for these collections, including some combination of:
- Find object, given the catalogue number.
- Select from list(s), of artists, subjects, and/or dates.
- Key word search, for matching viewer specified search terms to terms used in the catalogue title, type, creator, date, and/or description fields.
- Find similar to input object, for matching a scanned or drawn image, input from outside of the collection, with collection objects, as used by the State Hermitage Museum Web site.
a) View similar search, based on matching catalogue descriptions to those of a previously retrieved object.
b) Refine search, for modifying a previous search to expand or restrict the result set.
The results from a collection search are frequently listed without an apparent order. At least the viewer is frequently not informed of either the lists’ total length or of the relevance criteria used to order the result set. For example, a search for “Indian Child*” through the search facility of the Smithsonian American Art Museum at http://americanart.si.edu/study/ gave a result set, in which the first 3 items were:
|
“Woman and Child, showing…”, |
G. Catlin | 1837-1839? |
| “Buried Far Away, Cocapah”, | F. Rinehart | 1899 |
|
“Assiniboin Woman and child” |
G. Catlin |
1832 |
If the collection consists of images, the results commonly contain a list of thumbnail images, linked to a larger version of the image, plus an annotation giving the artist/creator, date, title, and perhaps location. If the collection consists of documents, the titles are listed and linked to the full text. Associations/relationships between the objects in the result set are not given, even though it is likely that there is a relationship between objects and documents describing them, particularly if the object has been used in an exhibit.
1.1 Information retrieval problems
The search strategies outlined above have a number of well-known problems based on the nature of communication and the mismatch between the knowledge level and language of the viewer and that of the creator of the collection. Another problem area lies in the (lack of) sophistication of the software search engines. For example:
- Search by catalogue number assumes
that the viewer has access to the catalogue. Given that the information
in the electronic DB is frequently a version of the catalogue, there
may be little new information to be attained.
- Selection from a list of artists,
subjects, and/or dates, assumes that the viewer knows the content and
time frame of the collection, something that is an unrealistic assumption
for general public viewers, particularly when the selection list consists
of the formal taxonomy for the collection.
- Key word search requires a language
match between the user/viewer and the collection creator, which is seldom
found.
- Matching a scanned or drawn image
input object from outside of the collection, with collection objects
requires a level of software sophistication that is not generally available
today (2002), except in very specific applications, such as fingerprints
or retina images.
- Retrieving similar objects, based on matching catalogue descriptions, commonly gives a high number of matched objects unless the extended search is limited to only a few of the catalogue characteristics. This function must be accompanied with a “refine results” function.
These problems are well documented in the information retrieval literature, as presented by Kowalski & Maybury (2000) and Baeza-Yates & Ribeiro-Neto (1999). There are also strategies for improving information retrieval from document collections that should be adapted to the more complex problem of information retrieval from multimedia museum collections.
1.2 Result presentation
Presentation of the results of an information search as an unordered list only indicates that each retrieved object has some relation to the selection criteria. This can be ok, if the user simply wants a list of all objects in a particular category, for example by a given artist. However, there is more information about the result collection available that could be utilized in presentation of the result set. Simple orderings could be by artist, chronologically by date of the objects, or by subject, style, or material. In addition, combining ordering criteria may give the viewer even more information.
Again, from information retrieval research and practice, the results can be ordered by relevance to the search criteria, assuming that multiple criteria are given and/or there is an importance/relevance distinction between matches in the title, keywords, and description of the objects.
Finally, the observed sites do not provide cross-referencing between collections, for example from an image collection to a document collection or to presentation within a virtual exhibit. Providing these links could significantly increase the information about the objects in the result set.
2. Designing virtual exhibits on demand:Ā applying a database management perspective
Museum exhibits, and their virtual counterparts, are crafted ’by hand’ on a case-by-case basis and include only a small portion of the museum’s real and electronic collections. Development of an exhibit takes months and several man-years of effort. The resulting exhibit is static in the sense that users cannot extend or tailor the content for their own special needs; for example, to form a specialized exhibit as an element in an educational context. Supporting user-developed exhibits, or specialized user defined collections, requires user access to the underlying data collections, possibly from multiple museums, as well as tools for search, retrieval, and presentation.
Museums maintain, and have made available on the Internet, an increasingly diverse set of electronic multimedia databases. As high quality recording and scanning equipment becomes affordable, document and image collections are being supplemented with audio, video, film, and 3D collections. Parallel digitalization activities have led to the development of sets of separate but related electronic data collections or databases. Given that museums house overlapping collections, the result is a large set of inter-related, Internet accessible multimedia, multi-database systems.
Two principal problems hinder support for location and access to multiple data sources.
- First, there is a lack of agreement on how semantically consistent
metadata for description of museum collections should be created.
- Thereafter, a query language and processing system must be developed to support the formulation of search criteria, search in a multi-database space, and integration and presentation of search results.
Our project aims to develop methods and tools to address these problems by integrating and extending existing methods and tools developed separately for metadata, multimedia, and multi-database management. Our interest lies in developing methods and tools for assisting development of virtual exhibits from a collection of underlying multimedia databases.
2.1 A user scenario
A student or teacher wishes to locate information on
the use of precious metals and gems in royal jewelry in Europe during the middle ages.
Relevant information is located in national museums, as well as national archives, libraries, and collections maintained for the royal families.
Using current Internet search engines, our user must perform the following tasks:
- Select one or more Internet search
engines.
- Enter the words of the above
requirement statement (keywords) as search criteria for the search engine,
which will:
- Match the keywords to site indexes created from site names and descriptions, and
- Return a list of (assumed) relevant Web sites.
- Use the result reference list to access a sub-set of the sites. At each site:
- Search via established links to locate relevant data, and/or
- Use the local search systems for database access.
- Finally, the user must construct a coherent presentation of the retrieved data and information, perhaps as a new virtual exhibit.
Known problem points in the above scenario:
- There are a number of search engines available, each giving a different set of responses to a query. For example: the above query retrieved 31 sites using “Ask Jeeves” and 101 when using “Google”. There were 6 references in the first 20 that were found (in different locations) in the 2 result sets and no references to museum collections.
- Internet search engines use indexes of Web (html) sites but are not capable of searching underlying multimedia databases.
- The user search terms may not match the descriptors – metadata – of relevant sites, and
- There is little or no standardization of collection descriptions (metadata), leading to
- The retrieved site lists may contain many irrelevant ‘hits’, i.e. which were clearly not relevant to the intent of the requirement statement.
- Site access from the result is an easy but tedious process, giving at best a mixed result consisting of segments of divers Web exhibits, and data from various museum collections.
- There is no uniform retrieval format to structure the collected information.
- There is no tool to aid construction of a new collection, as part of a document or perhaps a new virtual exhibit.
The problems can be summarized as a need for methods and tools to aid users in locating, accessing, extracting, and presenting relevant information from multimedia, multi-database systems developed and maintained by autonomous museums.
2.2 Current status in multimedia, multi-database management
There are a number of theories, methods, tools, and IT systems that can be extended to provide a solution for accessing autonomous multimedia, multi-database systems.
Resource Location & Metadata development
Location of relevant data and information requires that metadata describing the semantic content of each collection be made available in a standardized format that supports semantic integration [Bearman and Trant 1998]. There are numerous metadata standardization activities in process, perhaps best known are the development efforts behind Dublin Core in which there are 13 working groups including one with museum representatives. The Dublin Core effort began from the requirements of the Digital Library community and proposals for extension to other cultural application areas have been made, for example in [Bearman et al, 1999]. Other metadata proposals, developed for museum collection description include CIDOC [Doerr 1998] and the Warwick Framework [Lagoze1996]. Proposals for description of the semantic content of general multimedia can be found in [Lu 1999, Marcus 1996, Subrahmanian 1998, and Wu et.alĀ 2000].
The Dublin Core proposal (1999) consists of 13 basic metadata elements for describing aspects of media objects or resources. Controlled vocabularies are recommended for certain descriptive values; for example, for subject and type. However, it is well known that the use of controlled vocabularies for developing collection metadata/indexes requires trained users since the vocabulary seldom matches that of general public users [Hillman 2001]. This problem is also well known in the information retrieval community where much research has gone into linguistic based methods for selecting descriptive document terms and establishing thesauruses to aid the match between user query terms and the collection index terms [Baeza-Yates 1999, Kowalski 2001]. The problem is also well known in the multi-database research community where a structural analysis of database schemas has been the dominant approach for synonym resolution [Elmagarmid et.al 1999].
Data access and retrieval
As noted above, Internet search engines retrieve lists of Web site URLs after matching the user key word request with site indexes constructed from the metadata available to the search engine via crawler activity. No actual data is returned to the users who must then continue the search using the URL list and the established links on the referenced Web sites.
Multimedia database management systems, including document retrieval systems, also use a keyword-based search, but can also return actual resources (multimedia or document objects). These systems can also search for resources similar to a given resource, perhaps from the response to an initial keyword search [Baeza-Yates 1999, Kowalski 2001, Lu 1999, and Wu et.al 2000]. The problem with current approaches is that the search engine is specialized to one data type (text, image, video, audio, or spatial), thus requiring multiple queries, one to each data collection. Current Object Relational DB management systems, for example IBM’s DB2, can search for multiple multimedia data types within one database by combining access methods. However, these systems do not address the autonomous multi-database problem.
Current multi-database systems can search and retrieve data from multiple source databases, but only structured databases managed by relational or object-oriented DB management systems.
In both the multimedia and multi-database approaches, extensions to SQL3 are proposed and used, perhaps with a form interface. The major problem here is also that SQL3 is not a user friendly language as it requires user knowledge of the structure of the underlying database to be searched, an impractical restriction for an environment with a large number of multimedia data collections.
Presentation
Query results are generally given as a list of titles and/or thumbnail images linked to the objects/resources that are considered relevant to the search query. The list may be ordered by a relevance match between the query terms and the object descriptors. If the result is to be formed as an exhibit, the user must then do so.
2.3 A database perspective of exhibit construction
Figure 1 shows the main components for a planned ICT (Information and Communication Technology) system for construction of a virtual exhibit from the results of a multi-database query. The lower section of the figure illustrates the multimedia multi-database set, i.e. the environment of interest for retrieving information for an exhibit. Note that the figure shows only the databases for one museum/organization. The databases are assumed to be managed by an object-relational database system (for example Oracle or DB2) containing SQL3 as its access language and search functions for document, image, video, audio, and spatial/3D media objects. A catalog describes the objects in the database set.
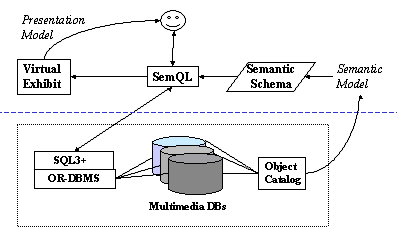
Figure 1: Virtual Exhibit system components
The upper part of Figure 1 shows the main components of a user interface for retrieving information from the database collection and presentation of the results as a virtual exhibit.
Resource Location & Metadata development
The interface is based on a semantic model of the object catalogs so that similar objects can be identified in the separate source databases. The ICT implementation of the model is termed the semantic schema and contains a ‘union’ of the local collection metadata as well as term thesauri for the collections.
Data access and retrieval
The SemQL query language is an extension of SQL3. Based on information from the semantic schema, SemQL is able to construct local queries to those databases that have data relevant to the user query. SemQL also has a user interface that is similar to those used in the advanced search functions of Web search engines with the addition of an interactive dialog system to assist with early refinement of the user query.
Presentation
A virtual exhibit construction module presents the results of queries to the system. The presentation module can construct a set of Web pages, a topic exhibit, for presentation of the query response. The resulting exhibit can be further modified by refining and resubmitting the SemQL query.
2.4 The virtual exhibit project
Bergen Museum, in Bergen, Norway, has embarked on a project, described briefly by Ramirez (2001), to establish and publish a number of different multimedia databases implemented by theme and media type. The project has funding from a grant from the Norwegian National Research Foundation (NFR), and the available databases can be found at http://museum.uib.no. The collection of databases currently includes 3D databases for sculpture and insects, a video database of centipedes, a film database from social anthropology projects, plus various text-document and image databases. At this time, the databases are not inter-connected and are not connected to virtual exhibits. When the first phase of the database set has been implemented, the system is to be integrated with similar systems in other Nordic museums.
At the Department of Information Science, University of Bergen, we’ve begun a project in cooperation with the Bergen Museum project, described in Nordbotten (2001), to develop tools that can utilize their databases for development of virtual exhibits. The framework for the project is given in Figure 1 above. This project is also supported by NFR and has funding for 6 researchers and graduate students.
Project goals
The primary project goal is to develop methods and tools for creating ’on-demand’ virtual exhibits from multiple multimedia systems, as illustrated in Figure 1 above. The new methods and tools are to be an integration and extension of appropriate methods developed separately for metadata, multimedia, and multi-database management.
Sub tasks for construction of a system for virtual exhibits on demand
The following methods and techniques will be developed in the coming 2 years:
- A semantic model for the metadata required for description of semantic
content metadata for museum data collections (databases).
- A method for integrating the metadata model from task1 with the basic
metadata model of Dublin Core, thus supporting interoperability with
other systems that use DC technology.
- A schema structure for storage of the metadata as required from task
1.
- SemQL as an extension of the SQL3 query language and processor to
support search by semantic content, as defined in the metadata
schema developed in task 3, for electronic museum artifacts stored in
multiple databases.
- An exhibit construction module for presentation of query search results.
Finally, a prototype system will be constructed and tested to demonstrate the feasibility and utility of above techniques in prototype system for an educational application.
The prototype will consist of 3 basic sub-systems:
- A metadata system tailored to museum collection users. Initially,
the “media abstraction approach” proposed by Marcus and Subrahmanian
(1996) and later extended by Subrahmanian (1998) will be used to develop
a semantic model for the museum collection. This media abstraction approach
outlines a structure for capturing the semantic content of multimedia
objects. It has not yet been developed into a working prototype, so
that our result can be considered method development. Assuming this
is successful, the result will be integrated with the semantic content
descriptions as specified in the current Dublin Core standard for description
of artifacts.
- The semantic query language SemQL, based on SQL3+, will be
developed. This language will combine the functionality of multimedia
and multi-database access as outlined in Baeza-Yates (1999) and Elmagarmid
(1999), respectively. In addition, SemQL, will use the semantic schema
structure developed under component 1 above. Currently, there is no
known query language that combines multimedia search in multi-database
systems.
- A generic exhibit generator will be developed for presentation of SemQL query results. We envision using a book metaphor for concurrent presentation of text and related image with embedded links so that the viewer can zoom from either the text or image presentation resulting in more detailed information presented in both text and image panels.
Test and Evaluation
Three phases of evaluation are planned:
- Prototype testing will be used to demonstrate the feasibility
of combining the above elements into a museum resource retrieval system.
- Precision & Recall measures, common in document processing
systems (Kowalski 2001), will be used for quality testing of SemQL.
The test environment will consist of a carefully constructed set of
data collections containing the scanned images and descriptive documents
for a set of thematically close types of museum objects.
- Usability testing will be done by eliciting thematic descriptions of presentation exhibits, defined by educators interested in the thematic content of the test databases. These will form the source material for the SemQL query and the presentation model testing.
3. Project status
The “Virtual Exhibits on Demand” project has 3-year funding from 2002, and consequently is just formally beginning. We have a team of 9 graduate students working together to explore aspects of the design and implementation for the system outlined above and expect that a number of master’s level theses will be developed in addition to a working prototype system that can function as a demonstration system for the concepts and functions described.
We would appreciate any comments and suggestions that the reader can give.
References
Baeza-Yates,R. & Ribeiro-Neto, B. (1999). Modern Information Retrieval. Addison Wesley.
Bearman, D. and Trant, J. (1998). Unifying Cultural Memory. Information Landscapes for a Learning Society, 1998. And presentation at UK Office of Library Networking Conference, July 1998. Also at www.archimuse.com/papers/ukoln98paper/index.html
Bearman, D., Miller, E., Rust, G., Trant, J., and Weibel, S. (1999). A Common Model to Support Interoperable Metadata, Progress report on reconciling metadata requirements from the Dublin Core and INDECS/DOI Communities. D-Lib Magazine, Volume 5 Number 1, Also at http://www.dlib.org/dlib/january99/bearman/01bearman.html
Doer, M. and Dionissiadou, I. (1998). Data Example of the CIDOC Reference Model. Epitaphios GE34604 Benaki Museum, Athens Greece. Also at http://www.geneva-city.ch:80/musinfo/cidoc/oomodel/epitaphios.htm
Dublin Core home site at http://dublincore.org
Dublin Core Metadata Element Set, V1.1 at http://dublincore.org/documents/1999/07/02/dces .
Elmagarmid, A., Rusinkiewicz, M., and Sheth, A. (1999). Management of Heterogeneous and Autonomous Database Systems. Morgan Kaufmann.
Hillman, D. (2001) Using Dublin Core. http://dublincore.org/documents/usageguide/
Kowalski, G.J. & Maybury, M.T. (2000). Information Storage and Retrieval Systems – Theory and Implementation, 2nd ed. Kluwer Academic Publishers.
Lagoze, C. (1996). The Warwick Framework - A Container Architecture for Diverse Sets of Metadata.ĀĀ D-Lib Magazine, July/August 1996. ISSN 1082-9873.
http://www.dlib.org/dlib/july96/lagoze/07lagoze.html
Lu, G. (1999) Multimedia Database Management Systems. Artech House, London.
Marcus,S. & Subrahmanian,V.S. (1996). Towards a Theory of Multimedia Database Systems. In Subrahmanian & Jajodia, ed. Multimedia Database Systems. Springer-Verlag, 1996. Pp 1-35.
Nordbotten, J. (2000). Entering Through the Side Door - a Usage Analysis of a Web Presentation. Proc. Int'l Confr.Ā Museums and the Web 2000. Minneapolis, MN, USA.Ā April 17-19.Ā Archives & Museum Informatics, 2000. p.145-151. Also at http://www.archimuse.com/mw2000/papers/nordbotten/nordbotten.html
Nordbotten, J. (2001). Virtual Exhibits - Theory, methods, and tools for development of virtual exhibits on demand. Project description. At http://www.ifi.uib.no/staff/joan/VM-project/project_description.htm.
Ramirez, E.A. (2001) Structuralizing Multimedia Data in Museums. The Use of Internet and Video and Scanned 3D Objects for Our Natural History and Science Museums. In Proc. of the ICOM International Conference in Barcelona, July 3, at http://www.lib.mq.edu.au/mcm/world/icom2001/ramirez.html.
Shneiderman, B., et.al. (1989). Evaluating Three Museum Installations of a Hypertext System.Ā Journal of the American. Society for Information Science, 40(3), 172-182.
Subrahmanian , V. S.Ā (1998). Principles of Multimedia Database Systems. Morgan Kaufmann.
Wu, J.K., Kankanhalli, M.S., Llim, J, and Hong, D. (2000) Perspectives on Content-Based Multimedia Systems. Kluwer Academic Publ.
Yamada, S., et.al. (1995).Ā Development and evaluation of hypermedia for museum education: validation ofĀ metrics. ACM Trans. of Computer-Human Interaction, 2(4), 284-307.
Museum sites referenced
Bergen Museum, Bergen, Norway, at http://mediabase.uib.no/Imagelib/
The National Library of Australia “Picture Australia”Ā at http://www.pictureaustralia.org/.
The New York Botanical Garden “The Virtual Herbarium” at http://www.nybg.org/bsci/cass/
The Sculpture Center's Ohio Outdoor Sculpture Inventory, at
http://sculpturecenter.org/oosi/oo.asp
The Smithsonian American Art Museum in Washington DC, at http://americanart.si.edu/study/.
The State Hermitage Museum, St. Petersburg, Russia at http://www.hermitagemuseum.org/html_En/index.html.
TAMH: Tayside A Maritime History, Scotland, at http://www.tamh.org/.