
Background
The National Digital Information Infrastructure and Preservation Program at the Library of Congress is an initiative to develop a national strategy to collect, archive and preserve the burgeoning amounts of digital content for current and future generations. It is based on an understanding that digital stewardship on a national scale depends on active cooperation between communities. The NDIIPP network of partners have collected a diverse array of digital content, including social science data-sets; geospatial information; Web sites and blogs; e-journals; audiovisual materials; and digital government records (http://www.digitalpreservation.gov).
These diverse collections are held in the dispersed repositories and archival systems of over 130 partner institutions where each organization collects, manages, and stores at-risk digital content according to what is most suitable for the industry or domain that it serves. This practice is necessary in a federated network of heterogeneous infrastructures but creates challenges in providing meaningful access across collections. However, it is clear that digital content grows in value exponentially as it is integrated and interconnected. As the Library of Congress and its partners develop a framework for a national digital collection, they have recognized a requirement to share and integrate partner collections in the interest of coherent strategy (Campbell, 2009).
NDIIPP partners understand through experience that aggregating and sharing diverse collections is very challenging. Transfer of data and accompanying metadata from one institution to another for integration into a different system is resource-intensive. The knowledge workers’ understanding of digital preservation content rarely translates to the understanding of systems and computer infrastructure that offer alternative means for sharing and aggregating such data. As such, the aggregation and consolidation of information about NDIIPP collections for Web resources have, to date, been a manual process. This is not a scalable strategy, and information becomes outdated as Partner systems and collections evolve.
Early in 2009, a pilot project recognizing the specific characteristics of this community was initiated by the Library of Congress and Zepheira. Working together, project Recollection was created. Project Recollection seeks to provide the platform, tools and environment that enables the community of NDIIPP Partners to share their collections and data on an ongoing basis. In addition, NDIIPP collections can be showcased from a central point through the activities of the Partners, and not the manual labor of the Library. This allows NDIIPP to maintain the benefits of a distributed network of partners and also take advantage of the collections speaking to one another (Campbell, 2009).
Specific goals for the Recollection project are to:
- Provide value through content rather than highly-specialized metadata
- Leverage existing principles to document best practices for digital preservation of content
- Build trust among NDIIPP Partners. Give the Partners incentive, tools and methods to work together to further curation of digital content on Recollection.
How It Works
The Recollection platform leverages a Web architecture and semantic Web technologies to contextually relate people, data, views and groups to enhance access for NDIIPP collections, making them easier to find, share, and especially to integrate with other digital information sources. The data that Recollection uses comes from a variety of sources produced by the NDIIPP partners. Excel spreadsheets, databases, XML, bibliographic records, etc. are just a few examples of source data types. The majority of the data that will be included in Recollection can be loaded directly to the system without massive customization; in fact, some of the data will be harvested right from Web sites. Data guidelines and an open interface will enable third parties to plug services and applications into the Recollection framework, encouraging community participation. Enabling reuse of the collections can support education, research, policy analysis and other uses which cannot even yet be anticipated. Because the platform provides a common framework for integrating dispersed collections and generalized tools for viewing this information, it is possible to analyze the collections which are being curated by each institution to help the network plan and execute its collection activities.
The following screen shot, for example, shows a new way of viewing a spreadsheet which contains information about the NDIIPP partners, their areas of work / interest ,and where they are located. While there is no actionable metadata captured in the metadata, the human curator can indicate which properties are geographical in nature. Using that new information, the Recollection platform can enrich the underlying metadata to generate latitude and longitude information which then allows the partner data to be viewed on a map.
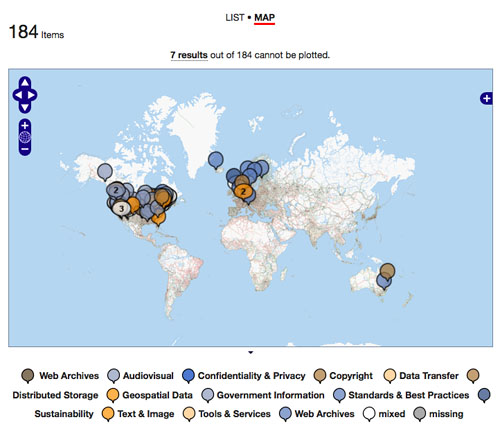
Fig 1: This shows a screen shot of viewing the NDIIPP partners spreadsheet on a map
Making it easy for the data curators to reflect their inherent knowledge of the underlying data, enhance it and easily create new ways of exploring this data through a wide range of front end interfaces provides new insights and opportunities for using this digital content.
The following sections provide an overview of how Recollection has extended the social computing model to support the management and sharing of data. It discusses the flexible interface visualization tools available in the Recollection platform, as well as the features which allow users to augment and enhance data. Future directions of this work will also be discussed.
Extending Social Networks for Data
Data sharing and quality have traditionally suffered for social reasons. Data is locked away on user desktops or in enterprise databases and hidden from those who need access, or who have information which may help improve it. Data is typically provided to users in filtered views that the data provider believes are useful, but these are assumptions which may bear no relation to actual user needs. Between user and provider, there is little opportunity to have a dialogue about the data and even less chance of exploring alternative ways of looking at it.
Users figure prominently, as in any social network. One of the purposes of Recollection is to help build trust among NDIIPP Partners and give them incentives, tools and methods to share data and work together effectively. To facilitate social connections, Recollection extends the traditional concept of social networks to include data, data curation and views of data in order to allow the community to unlock its potential based on their collective knowledge. Recollection attempts to equally and symmetrically expose four types of objects to the world: people, data, views, and groups. We call the four objects "first class" because the relationships between them define the non-administrative workflows of the environment.
First class objects have natural relations to each other that are reflected in a formal manner within the system. A view is based on data. Data is loaded by a user. A user is connected (in various ways) to other users. Groups have members (that can be users, data and/or views). Relationships between first class objects are intentionally bidirectional and symmetric.
While the underlying contextual infrastructure, based on semantic Web principles, is general, the specific relationships that are exposed in any instance of the Recollection platform is reflective of specific community needs. Relationships, representative of policy or sharing practices, may differ from community to community. These policies in Recollection can be defined for each instance of the platform. Further, extensibility and refinements of these relationships which reflect the changing requirements of the community over time are possible so that new functionality can be layered without breaking existing systems.
In the Recollection platform serving the NDIIPP partners, an initial set of relationships is defined in a manner to support the early formulation of this community. Users are ‘connected’ to each other. A view is ‘based on’ a dataset. A user is ‘a member’ of a group, and so on. These high-level relationships are reflected in the following snapshot of a user’s home page connecting people, data, views and interests.
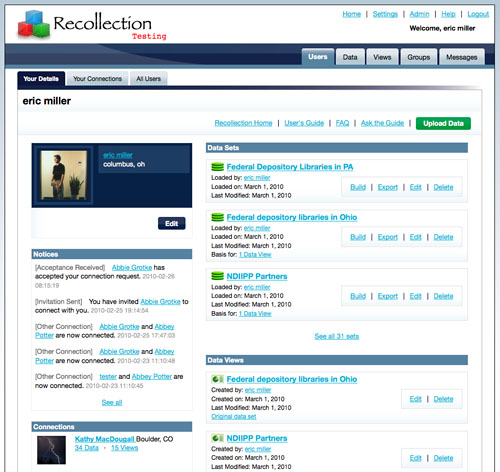
Fig 2: A user’s home page connecting people, data and views in Recollection
First class objects have natural relations to each other. A view, like data, is created by a use and has contextual relationships with other users (as friends or colleagues who work for the same organization, or share the same topical interests). Views and data profiles may be related to a topical group so that members of each group can easily share subject-based information. Relationships between first class objects are intentionally bidirectional and symmetric.
Data may have multiple views built upon it. That is, if a one user uploads a data set, other users may use the same data to create their own individual views. All users have the opportunity to view the data as they see fit, in the way that makes the most sense to them. One user may create a view that plots location-based data on a map and time-based data on a timeline. Another user may wish to pull numerical data from the same file and plot it on a scatterplot or bar chart. Multiple views can exist side-by-side on a given Web page, allowing for rapid viewing of the same information in different ways.
Groups allows for the creation of communities around common areas of interest. Data, views and discourse relevant to these common interests can be shared within a group. Groups promote topical, organizational or geographical discovery. Groups provide a collection-based means of sharing knowledge within the community.
Group members can discover data sets provided by others which, when connected to their own data set, may enhance its value. For example, imagine a group whose area of interest is gardening. One user may have a personal spreadsheet of vegetables which they've been thinking about planting that year. Another community member may have access to a complete listing of vegetables, along with their suggested planting dates and gestation periods to grow. Merging these two data sets would provide new insights into when and how best to structure and plant one’s garden. The fruits and vegetables from one’s garden can then in turn be merged with another member’s favorite recipes to help zero in on the best meals that match the ingredients ready for harvest. There is an open-ended set of possible options for stitching together data. The Recollection platform is designed to reduce the cost in allowing such exploration and sharing.
Data curation has typically been a task assigned to a handful of expert users who have been given special permission to add to and modify it. Centralized control of data has been seen as essential to maintain data quality, but is often an impediment. By opening up the data, Recollection gives the community a vested interest in improving the data as well as a forum in which to communicate these improvements. Providers of the data are given incentive to ensure a higher level of quality as they know their data is being viewed and shared with others. Users of the data have a vested interest in communicating errors they find back to the data owner, or in fact, correcting it themselves, since they want the views that are built from such data to be accurate.
Faceted Views as Visual Cues for Understanding and Curating Data
As easy as it is to load data into the system, it is equally easy to create a wide range of views of this data. Without any coding, users of Recollection are able to create faceted means of navigating their data. Recollection provides the end user the ability to easily create Exhibits without any knowledge of programming HTML or Javascript (Huynh, 2007). Exhibits are one of the several deliverables of the MIT Simile project, which focused on developing robust, open source tools that empower users to access, manage, visualize and reuse digital assets (http://simile.mit.edu). Exhibits provide a light-weight means of creating flexible interfaces that allow collections to be searched and browsed using faceted browsing. Faceted browsing allows the assignment of multiple classifications to an object, enabling the classifications to be ordered in multiple ways rather than in a single, pre-determined, taxonomic order. Each facet typically corresponds to the possible values of a property common to the data set. Users can select which properties might be useful as facets and navigate these via traditional lists or tag clouds.
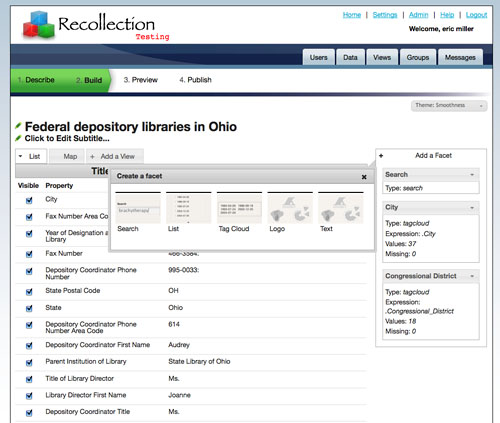
Fig 3: Creating facets in Recollection
The results of faceted browsing are equally configurable by the user. Result set items that are specific to faceting browsing can be viewed in customized list views, displayed on a map, rendered on a timeline, or presented in a bar chart or scatterplot diagram. Users are easily enabled, through a series of point and click interface options, to create a wide range of views that are specific to the data. Empowering users to be able to choose the facets that they find of particular interest as well as a range of customized views to see the results allows for quick and easy ways for users to explore data.
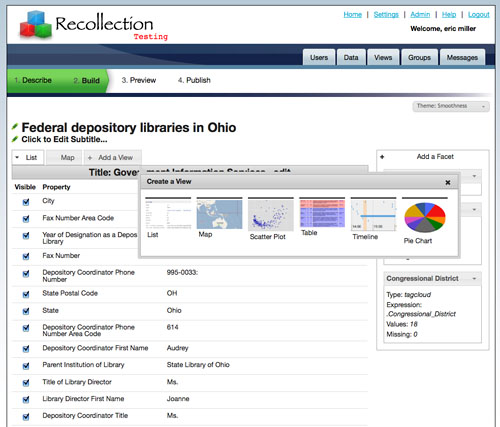
Fig 4: Customized views in Recollection
The ability for Recollection to quickly empower the end user to create a wide range of Exhibits from any data set and consequently create a range of specific views of this data allows for new insights and the potential for digital preservation of data. Further, empowering data curators with a means to create new interfaces over their data providing quick visual cues highlights any inconsistencies or errors associated with their data.
Human Annotation and Semantic Augmentation of Data
An important design criterion for Recollection is to facilitate multiple and differentiated views of data. In Recollection, data may be displayed in lists or tables, plotted on maps, timelines, scatterplots, pie charts, etc. If location data is present, then a map may be appropriate. If temporal information is present, then a timeline view may be appropriate. Numerical data may suggest plots of various types.
Unfortunately, the lack of standardized input formats for common data types, such as dates, times, and locations, makes it difficult to guess a user's intent. Lack of standardized input formats,however, is a reality, and asking everyone to agree to describe content based on common standards is an extraordinarily difficult social engineering task. Although it is certainly possible to attempt to introduce a wide range of less than successful heuristics and address this type of problem technologically, an underlying premise of Recollection is that users know more about their data than machines do. Recollection instead approaches the assignment of metadata socially. Upon data upload, users are presented with an interface that allows them to manually assign data types to data elements. The curation of this data is encouraged by the simple fact that users wish to achieve a particular task (e.g. wanting to place the data on a map).
Humans have an ability to identify patterns in information that far surpasses the current state of artificial intelligence. Strings such as "December 11, 2009", "11/12/09", "11Dec2009" are quickly understood to be dates. A property name that is defined as “dc:coverage” may, to those knowledgeable, signify the fact that the values associated with it may be geographical in nature. Strings that follow patterns such as “fruit, cheese, bread, milk” may instantly be recognized as lists. Recollection leverages the concept of “data augmentation” which enables the user to explicitly describe these recognized patterns and then leverage machine processing to create more actionable data that can visualized in new ways to share with others.
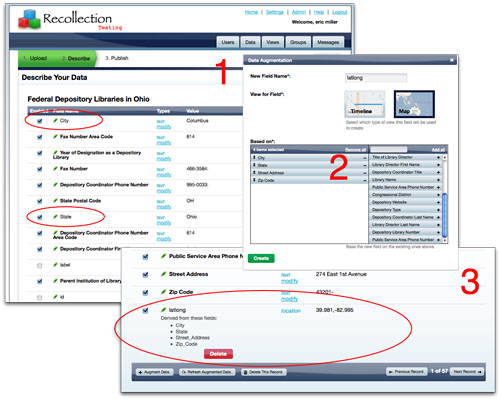
Fig 5: Data Augmentation in Recollection
In Figure 5, for example, the user identifies fields that reflect geographic location. By selecting all of the fields that correlate to a place, the application is able to augment the existing data and provide latitude / longitude location which can then be used to easily display the data on a map.
Exposing Data and Views Back to the Web
One of the key aspects of Recollection is to minimize any of the traditional ‘walled-garden’ approaches to social networking systems. If the appropriate policies are set in Recollection, data can be easily added via RESTful (Fielding, 2000) Web interfaces and the associated views generated from data made available outside of the Recollection system. Generated views of data are bootstrapped from HTML Exhibits which are dynamically served via a template. The HTML generated from these templates includes Javascript libraries, CSS stylesheets, and the underlying data. Unfortunately, the minimal HTML scaffold so simple that it does not provide adequate information for search engine crawlers to index the generated content in a meaningful way (Huynh, 2009).
The Recollection platform has addressed search engine indexing by means of the RDFa metadata markup language (Adida, 2008). RDFa markup is added to generated HTML scaffolding at resolution time for a view's URL. Support for RDFa indexing by major Internet search engines is a rather new phenomenon. The two largest search engines, Google and Yahoo!, have recently announced support for both indexing content including RDFa and building search results based on RDFa information (Goer, 2008) (Goel, 2009).
In addition to exposing RDFa metadata to the Web for better search engine discovery, the Recollection platform also provides a means for embedding any of the views (if policy restrictions allow) into arbitrary Web pages. Thus the Exhibits that users create on the Recollection platform can be, with a small HTML fragment, viewed outside of the platform on partners’ Web pages, blogs, etc.
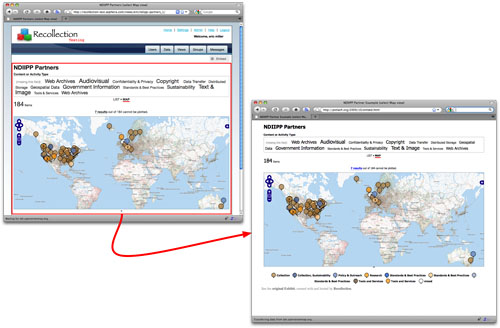
Fig 6: Embeddable exhibits via the Recollection platform
By exposing more machine processable metadata about digital preservation data to the Web and enabling views of data to be easily embedded in other Web pages, increased access to the underlying digital preservation data and associated views is provided.
Future Work
The Recollection platform is currently in internal beta testing phase, with evaluations occurring both at the US Library of Congress as well as with an initial set of invited NDIIPP participants. A more open beta release involving more of the partners is expected later this year.
Recollection is based on the Freemix platform, an Open Source Software project, but extends Freemix with both software and third-party data services. Recollection leverages Akara (http://www.xml3k.org/Akara) as a powerful open source transformation pipeline engine to provide data transformation services and rapid support of new data formats. However, central management of available data transformations is currently enforced. It would be useful for end users to have the ability to extend data transformation capabilities for their own use and for others to be able to reuse them. Some form of data transformation marketplace may be needed.
Privacy and access restrictions are defined at the community level. Early users of Recollection have either been publishing public information (NDIIPP) or been forced to limit themselves to information they wish to make public. Business and government users have expressed interest in access control mechanisms. The current Recollection architecture is designed toward supporting a more sophisticated policy aware framework, but at this time, user requirements have not yet merited such functionality.
The Recollection platform currently provides the ability to generate multiple views from any given data set. The ability for users to easily mix multiple data sources together (at both property and value space) is currently underway, but remains an active area of work. Further hardening of this capability is expected later this year.
Conclusions
Recollection provides a useful intersection of social networking practices and data manipulation to promote sharing and curation of information. This paper provides a brief overview of the Recollection framework and discusses how Recollection has extended the social computing model to support the management of data, and to provide flexible interface visualization tools to allow users to augment and enhance data.
Acknowledgements
Special thanks to the folks at the Library of Congress, Office of Strategic Initiatives who have helped make this project successful, including Laura Campbell, Martha Anderson, Jane Mandelbaum, Abbie Grotke, Abigail Potter and Gina Jones.
Our thanks to the following: Open Standards, Open Content and Open Source Software communities for providing the critical building blocks that underpin the Recollection platform: The World Wide Web Consortium for RDF and RDFa, Creative Commons for Open Content licenses, The MIT Simile Project (http://simile.mit.edu/) for Exhibit and Simile Widgets, Freemix Core for the social community, data management Exhibit building capabilities (http://freemix.it/), The Akara Project for the Akara data transformation pipeline (http://www.xml3k.org/Akara), the Django Project (http://www.djangoproject.com/) and the Pinax Project (http://pinaxproject.com/) for the Django Web framework and related applications.
References
Adida, B. and M. Birbeck (2008). Rdfa in xhtml: Syntax and processing. http://www.w3.org/TR/xhtml-rdfa-primer/
Campbell, Laura E. (2009). Recollection: Integrating Data through Access. The Library of Congress, ECDL. http://purl.org/net/ndiipp/ecdlpaper
Fielding, R. (2000). “Architectural Styles and the Design of Network-based Software Architectures”. Doctoral dissertation, University of California, Irvine. Available: http://www.ics.uci.edu/%7Efielding/pubs/dissertation/top.htm
Goel, K., R.V. Guha and O. Hansson (2009). Marking up structured data. http://googlewebmastercentral.blogspot.com/2009/05/introducing-rich-snippets.html
Goer, E. (2008). Searchmonkey support for rdfa enabled. http://tinyurl.com/yahoosearchmonkey-rdfa
Huynh, D. (2009). Google's rich snippets in exhibit. http://tinyurl.com/huynh-googlerichsippets Consulted May 22 2009.
Huynh, D., R. Miller and D. Karger (2007). Exhibit: Lightweight Structured Data Publishing. ISWC,. http://davidhuynh.net/media/papers/2007/www2007-exhibit.pdf
NDIIPP. National Digital Information Infrastructure and Preservation Program, http://www.digitalpreservation.gov