Introduction
The Oral History of Illinois Agriculture (OHIA) project is supported by a two-year IMLS National Leadership Grant awarded to the Illinois State Museum (ISM). The purpose of the OHIA project is to develop new digital oral-history resources telling the story of Illinois agriculture and to encourage active audience use of these resources in on-line and museum settings. The project is creating an interactive Web site – the Audio-Video Barn – featuring digital oral-history interviews with people involved in various aspects of agriculture and rural life in Illinois. Some of the interviews have been digitized from audio tapes archived in libraries at Northern Illinois University and the University of Illinois at Springfield. In partnership with the Abraham Lincoln Presidential Library and Museum (ALPLM), we have also recorded more than fifty new interviews with a diverse array of people of various ages from throughout the State of Illinois. Most of the new interviews have been recorded with digital camcorders so that video images as well as sounds can be made available on the Web site. Audio and video files have been digitized (when necessary), edited, and transcribed. Interview files have also been indexed by theme, topic, and geographical location so Web visitors can search them interactively for subjects of special interest.
Gathering and Building the Data
The interviews
Many of the interviews featured in this project were chosen with help from two regional archives, University of Illinois, Springfield (UIS), and Northern Illinois University (NIU). These interviews were chosen with emphasis on agricultural work and life. All of the archival interviews are audio only and, with one exception, date from the 1970s, 1980s, and early 1990s. The Brookings Library at UIS provided digital versions of forty-two interviews dating from 1972 through 1993. The Regional History Center at Founders Memorial Library, NIU, provided access to analog audio recordings (cassette tape) in its oral-history collection. The collection includes eighteen interviews that have significant agricultural content, all conducted in 1986. One additional interview in the ISM collections was recorded in 1954.
ISM and ALPLM shared the task of conducting new interviews, originally planned to be fifty, but eventually expanded to seventy-eight, forty-seven by ISM and thirty-one by ALPLM. These new interviews are video, some in standard DVD definition and others in high definition, and were conducted from 2007 to 2009. The new interviews are not only in standard “sit-down” format, but many also are in a “walk-and-talk” format in which the interviewee, camera operator, and interviewer are in the field, orchard, or other agricultural facility. The new interviewees were chosen not as a representative sample of agriculture in Illinois, but rather to illustrate and record the diversity that exists in Illinois farming at the beginning of the 21st century.
Indexing the interviews
The new and archival interviews consist of over 300 hours of discussions, mainly focusing on aspects of agricultural life. All but the eighteen NIU interviews have full transcripts, although some of the UIS transcriptions are provided as scanned images of typewritten pages. The most common method for using oral histories is the use of text transcriptions – the raw data of the audio or video recordings has always been too time consuming to search. However, the goal of this project was to produce a Web site that would allow easy thematic searching, filtering, and navigation through the interviews.
In developing this goal we were guided by our partnership with Randforce, Associates. Randforce is an oral history consulting company that specializes in digital indexing of audio/video interviews, using software called InterClipper. InterClipper is essentially a linear single-track multimedia editor combined with a relational database – InterClipper Pro works with audio files, and InterClipper Video works with video files. Using InterClipper Pro, the user views the entire interview in wave form and, using sliding widgets, can mark and annotate portions of the interview. Figure 1 shows a screen shot of InterClipper Pro.
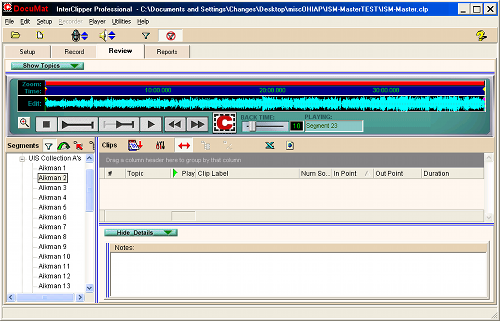
Fig 1: InterClipper Pro screen shot. In this case each line labeled “Aikman *” is a single WAV file, representing one side of a cassette tape
In our implementation we wished to make the entire interview searchable, but we also wanted to target short and particularly interesting clips. Our method was to cut the interviews into two types of divisions we term “segments” and “story clips”. Segments are contiguous but topically non-overlapping portions of the interview and encompass the entire interview, analogous to chapters on a commercial DVD. Segments are usually around 5 to 15 minutes in duration. Story clips are short, often around 1 minute in duration, and very focused on one subject.
The first step was to define a series of contiguous but topically non-overlapping segments that encompassed the entire interview. First the audio graphic was examined for obvious, visual breaks in the graphical representation of the interview. Once defined we refined the in and out points of each segment to make sure a topic at the end of one segment did not carry into the adjacent segment. After the boundaries were defined, the segment was carefully reviewed and a series of notes were recorded consisting of synopses and indexing using control words (see Figure 2).
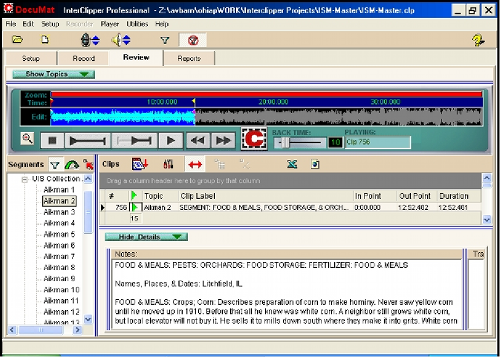
Fig 2: One segment with associated notes
InterClipper has built into the default database a 3-field structure of categorizing and indexing, but in initial testing of our data we decided that the default method would not provide enough flexibility for our goals. Instead, we decided to construct the notes in a rigidly structured form and depend on the parsing abilities in the PHP scripting language to pull out the content for the final Web site.
Here is a short example of notes for a 5:30 minute segment from a vintner interview that covers two subjects:
FARM BUSINESS: REFLECTIONS
Names, Places, & Dates:
FARM BUSINESS: Bookkeeping: Have to plan ahead, do the math, predict what expenses and income may be long term.
REFLECTIONS: Values; Wine: Has inner drive that gets him up at 4:30am and work until 6pm to make the best wine. He has expanded, now he will just develop what he has. (This clip is available at: http://avbarn.museum.state.il.us/viewclip/2611)
The first row has the two main subjects (controlled vocabulary). The next row of text contains person names, place names and/or dates (largely decades) separated by semicolons, all of which are empty in this case. Finally there is a series of paragraphs, one for each of the main topics in the order in which the topics occur in the segment. Each paragraph begins with the topic followed by a colon and then by one or more sub topics separated by semicolons and ending with a colon. The rest of the paragraph has a free form synopsis or abstract of the discussion of the topic.
Some segments cover just one topic, but most cover several different topics. Ideally we would have cut up and indexed the interviews so that each separate topic would be available individually to the visitor. However, the initial testing indicated that completing such precision of indexing would not be possible within the time span of the grant. In order to maximize the precision of our indexing, but still make it possible to index every minute of interview, we developed the idea of the “story clips.”
As the indexers were listening to the interview, they would watching for interesting little sound-bite parts of the interview. These would be short, hopefully a minute or less, and only cover a single topic. These would be marked and given a descriptive title, often an attention-grabbing quote from the clip. The notes would be constructed in the same way as those for the segments. Here are the notes for a 1:34 minute clip by Bert Aikman discussing his experience with beekeeping soon after WWII.
BEEKEEPING
Names, Places, & Dates: 1940-1950; Centralia, IL
BEEKEEPING: Honey; Dutch-White-Clover; Productivity; Sugar; Community Service: Bert talks of how bees made good honey when Dutch-White-Clover is available, & that he had 350 lbs of honey he couldn't sell [after sugar-rationing ended?]. He donated the honey to a Baptist Orphanage in Centralia, IL. (This clip is available at: http://avbarn.museum.state.il.us/viewclip/1777)
The structure of the notes is the same as that listed above in the Segment on FARM BUSINESS: the main topic(s), a line for names of persons and place, and dates (this time with the decade 1940-1950) and (Centralia, IL) and one paragraph for each main topic (usually just one for story clips). The summary paragraph starts with the main topic, followed by one or more sub topics associated with the main topic, and a free-form synopsis of the clip. In this case the indexer has added an annotation suggesting that Bert's inability to find a market for his honey was due to the end of sugar rationing.
“Final” editing
We found that although InterClipper is a fine tool for indexing, it lacked some features that were needed for our project. Our decision to move from the default method for indexing – which includes pull-down menus for the controlled vocabularies – in favor of the structured text field of the notes, resulted in a problem of maintaining consistency in terms. Therefore we moved the data from InterClipper into MS Access for further editing, giving us the ability to run search-and-replace operations, as well as spell check. This editing process was more of a cyclical process. Soon after the first migration of InterClipper to Access, we began the process of migration to MySQL. As we developed the migration, we were able to identify the records that would not migrate, or provide lists of keywords that would help identify inconsistent terms.
Publishing the Data
The interview indexing stage resulted in 3,566 distinct segments or story clips. The next stage was to translate and migrate this effort to the Web. The goal was to produce a site that would allow flexible searching, filtering, and navigation through the interviews.
Choosing the tools
Where possible, we wished to use freely available software for our development. However sometimes such software did not exist to meet our needs. For example, video editing for the digital files created by the Sony High-Def video camera was found to be unavailable. Also, individual familiarity with software is important, and so the intermediary editing between InterClipper and MySQL was done in MS Access.
We are very familiar with the standard Web site suite of applications of Linux, Apache, MySQL, and PHP (often termed LAMP), and this is the platform that we used. The first iteration of migration to the Web was built directly in PHP. This allowed navigation through the database, full-text searching of the notes, and filtering based on the controlled vocabulary. It worked, but it was quickly clear that other features, such as the development of content management forms for pages or lesson plans, would take as much effort as the interesting part of the project (the oral history).
We began looking over options for content management systems and narrowed the search to three: Joomla, Omeka, and Drupal. We chose Drupal because of two main features. First, the program allows easy to creation of new content types through the CCK (Content Construction Kit) module and associated modules. Second, Drupal provides a flexible method of data display through the Views module. These two features make Drupal remarkably developer-friendly, if not user-friendly.
Migrating the data
As it turned out, we were quite lucky in our timing. In January of 2009, just as we started the migration from InterClipper to Access to MySQL to Drupal, the developers at Cyrve.com released a DEV version of the twin modules Table Wizard and Migrate. Table Wizard allows the integration of non-Drupal MySql tables with Drupal, and Migrate allows the translation of those tables into Drupal content types.
The migration of InterClipper to Access was done by Doug Lambert of Randforce. There are many tools available for moving data from Access to MySQL. Under Linux we used parts of the “mdbtools” suite, easily available for any Linux distribution to export the data to delimited text, which we then read into MySQL through the phpMyAdmin Web application.
The original structure of the InterClipper database consists of five tables, three of which are important to our project. See Figure 3 for a graphic representation. The three main tables consist of:
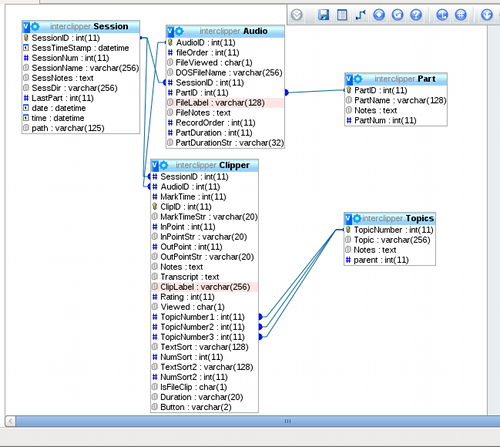
Fig 3: Structure of original InterClipper database
SESSION: In our project a session is a group of interviews from a particular source: University of Illinois-Springfield, Northern Illinois University, Abraham Lincoln Presidential Library, or Illinois State Museum. We also vary types of interviews; for example sit-down or walk-and-talk.
AUDIO: This table consists of one record per digital file. For example, the interviews from UIS and NIU were originally on cassette tape, and had been digitized to one file per side of tape. The AUDIO table contains information about the interviewee, the order of sequence of this file within the session, physical location of the digital file media, and also a SessionID value that ties back to the SESSION table.
CLIPPER: The clipper table is the central table and contains the information for the individual segments/clips indexed in InterClipper. This information includes beginning and ending points, clip title (label), the Notes, and SessionID and AudioID, which tie back to the SESSION and AUDIO tables. The remaining tables in the original InterClipper structure, PART and TOPICS, were not used in our project.
Creating Drupal content types
We decided to largely mirror the InterClipper structure in the Drupal implementation by creating new content types for Session, Audio, and Clipper. Every entity within Drupal is a ‘node,’ and a node always carries along some basic fields, such as Title, Body, Teaser (a short bit of text to show in lists), Authorship, Date/Time of posting and last edit. For Session and Audio, very little needed to be added to the standard content types. SessionID, and AudioID were added for relationships to the clips, and we also added a Biography content type to hold interviewees’ information, which is linked from the both the Audio and Clipper tables.
The Clipper content type holds the information particular to each indexed Segment or Story Clip and is the atomic level of the interview data in this project. Every search or filter operation results in the return of a list of rows from the Clipper content type. Wherever we wanted to allow searching, filtering, or sorting, we had to provide a separate field for that option. Therefore the Clipper content type has a large number of fields, as well as several associated ‘Vocabularies’ that hold the associated ‘Tags’ gathered from the control words (Keywords, or Topics) assigned during the indexing phase. Figure 4 shows the listing of fields in the Clipper Content Type.
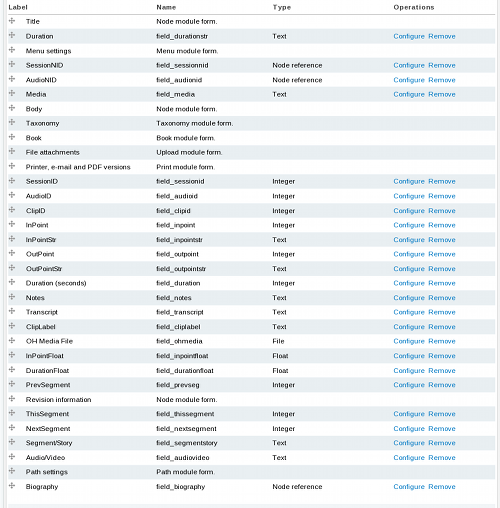
Fig 4: Field structure of the Clipper content type. Rows that list “Configure Remove” are custom fields used with this project. Other rows are core Drupal fields.
I will not describe every field here; however, some may need explanation. The Notes and ClipLabel fields are directly copied from the fields of the same name in the InterClipper database. These are not displayed to the visitor, but are available for searching. The Title and Body are displayed to the visitor and are derived from ClipLabel and Notes respectively, but contents of both may be modified. The Body in particular is modified by stripping out the “Name, Places & Dates” paragraph, the sub topics, and translating the paragraphs into an HTML Definition List (<dl></dl>).
InPoint and OutPoint are expressed in seconds and represent the beginning point and end point of the Segment/Clip. These also are not displayed to the visitor, but are used in views to display the contents of an interview in a temporally correct order. These values are also used to populate the fields PrevSegment, ThisSegment, and NextSegment. These three fields are used to display “Next” and “Previous” navigation links, allowing the visitor to navigate through the interview.
The OH Media File field contains text formatted in the form <swf file=”clipper/***.mp3”> or <swf file=”clipper/***.flv”>. When Drupal displays this field, a filter translates the text to the proper code to display the flash-based player for the audio (mp3) or video (flv) file. The “***” is replaced by the value of ClipID.
SegmentStory and AudioVideo contain strings that indicate whether the item is a Segment or Story Clip, and whether it is video or audio-only clip. These are then available as filters for the visitor.
And finally, Biography contains a link to the biographical description of the interviewee. This is used to provide an image and short description of the person on every page for a Segment/Clip.
The association of each clip to topics is handled by Drupal outside of the fields that you see above. It was assigned at the point of migration into Drupal based on fields derived from the Notes. Most of the fields within the Clipper content type required preparation before the migration could occur.
After the InterClipper data were moved from Access to MySQL, a series of three php scripts were run to prepare a table for the Table Wizard/Migrate modules in Drupal. Because these were scripts, the migration process could be done fairly quickly whenever updated versions of the Access database were available. It also provided feed back to the indexer or editor by identifying records that had problems. These three scripts were, in the order in which they were applied, combine-clippers.php, parse-notes.php, and get-prev-next.php.
Combine-clippers.php: This script has one function. It combines the data from three separate InterClipper projects into one table. At first we did all the indexing of interviews in one ‘project’ using InterClipper Professional. Later we decided, because of scheduling requirements, to index the Walk-and-Talk interviews separately using the sister product, InterClipper Video, one ‘project’ for ISM interviews and another for ALPL interviews. The InterClipper products maintain unique SessionID, AudioID, and ClipID values only within a ‘project’, and we depended on unique ID values for each of these; therefore we developed this script to renumber the ID values in a consistent manner.
Parse-notes.php: This script does the main preparation of the data for migration. Its most important function is to pull apart the contents of the Notes field into the constituent paragraphs, parse and process the contents of each paragraph for the Body to display, and identify keywords to include as vocabulary tags.
For example, if the notes look like:
BUTCHERY
Name, Places, & Dates: 1930-1940
BUTCHERY: Cattle; Hogs; Canning; Food & Meals: Butchered beef and hogs, but not on a large scale or in with others. Canned the meat.
the value “1930-1904” would be placed in a field for Date tags to be migrated to the Date vocabulary. The terms BUTCHERY: Cattle; Hogs; Canning; Food & Meals would be placed in a field for Animal tags. And the value of the Body would be set to:
BUTCHERY
Butchered beef and hogs, but not on a large scale or in with others. Canned the meat.
The choice of which vocabulary (Land, People, Plants, Animals, or Technology) to place the terms in is based on a look-up table derived from the 315 distinct main topics used for indexing. Each of these terms was identified with one or more of the main categories: Land, People, Plants, Animals, and Technology, which serve as the primary thematic structure of the project.
This script would also identify whether the clip was audio or video, based on the presence of a clipid.mp3 or clipid.flv file on the server. If neither file was present, it was marked as no-media.
Get-prev-next.php: This final pre-migration script would search through Segments and, using the In and Out points, would find the ClipID values for previous and next segments (zero if at beginning or end of the interview portion). It then would search through the story clips and identify the segment that contains this story clip, again through the use of the timestamp information.
After running these scripts, the new table was ready for migration into Drupal. The Migrate module uses a concept termed ‘content-sets’ where one identifies the destination content type, and how to map source and destination fields. Figure 5 shows a portion of the content-set page. You can, for example, see that the source field ClipLabel is mapped to the Drupal filed Node:Title.
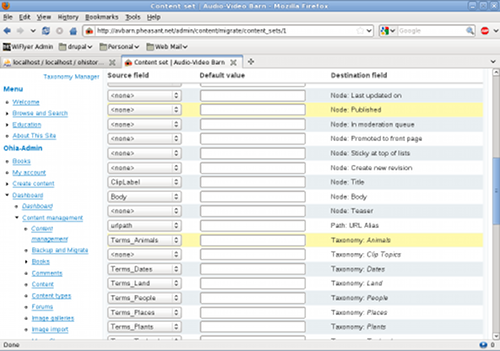
Fig 5: Portion of the field-mapping page for the Drupal Migrate module
The Migrate module keeps track of errors, which one may view to help identify the source of problems. It also maintains a map or lookup table that can link together each source row with the newly created Drupal node. We used these map tables in one script run after migration to populate the node reference fields; for example, a reference from a clip to the person in the clip. Some of these values cannot be built until after the migration because Drupal creates new Node ID values each time.
Summary
To summarize, we started with sixty-one archival audio oral history interviews, chosen because they generally were focused on farming. We also conducted seventy-eight new video interviews with a wide range of people who are currently involved with agriculture in some way, resulting in a total of over 300 hours of interviews. Following the lead of our partners at Randforce & Associates, we indexed all interviews by controlled keywords and developed synopses for every portion of the interviews.
Although the tool used for indexing the interviews, InterClipper, works well for that purpose, we found that for extra editing we needed to move the data to another platform. For that editing we chose MS Access. Additional processing was done in MySQL via custom php scripts, and the result of that was migrated into Drupal.
Moving content such as these indexed oral history interviews into Drupal is a challenging process, but one gains a great deal of functionality once the data are fully within the Drupal framework. In particular, the Drupal application allows rapid development of multiple methods of navigation through content. This is important in cases like this in which the content is complicated and has topics which range so widely. For our team, the first time that the ‘Faceted Search’ module was installed and enabled was an exciting day (Figure 6 shows the Faceted Search page). Suddenly we could see the depth and breadth of the collection we had created.
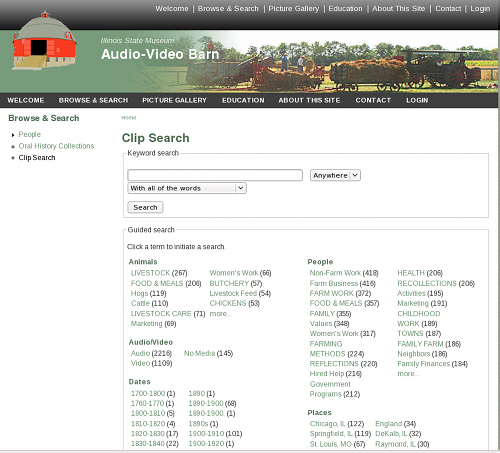
Fig 6: First page of faceted search page on A-V Barn Web site.
Part way through the project we hosted a testing-and-workshop event for several K-12 teachers. We introduced them to the prototype Web site and after a small amount of demonstration and free exploration time, we asked them to develop draft lesson plans based on this resource. All were able to accomplish this, but it was interesting to watch how they did it. Each person had a different way to begin: some had definite topics in mind, others not. Some started by typing into a search box, others liked to start at the “top” by choosing interviews from a particular institutional, and then drill down and browse titles. Still others started with interviewee pictures and biographies. Not one of the teachers liked tag clouds. They all liked faceted search, even if they did not choose it as a first option. This workshop helped shape the final development of the Web site with the goal to allow as many different ways to navigate through the interview data as possible. We already look forward to our next project.
Acknowledgments
Although I'm a single author here, this project was a product of many. For more information and a full list of staff and volunteers, visit the “about” page at: http://avbarn.museum.state.il.us/about
Dr. Robert Warren (Illinois State Museum) was Principal Investigator of the project, Dr. Mark DePue (Abraham Lincoln Presidential Library and Museum) was Principal Investigator, and both conducted many of the new interviews. Michael Maniscalco (Illinois State Museum) was project coordinator, and also conducted many of the new interviews. James Oliver (Illinois State Museum) oversaw the indexing project; Sue Huitt (Illinois State Museum) developed the educational content. Dr Michael Frisch and Doug Lambert (Randforce) taught us about oral history and digital indexing. Tom Clark (TA Consulting) performed our project evaluation. The project was supported by a generous grant from IMLS.